VPC FlowLogs を S3 に保存しAthenaで抽出する方法#
概要#
本資料は VPC FlowLogs をS3に格納し、Athena にて トラフィックを分析する手順を記載します。
- 1.S3バケットの作成と設定
- 2.VPC FlowLogsの設定
- 3.Amazon Athenaでの取り込み設定と動作確認
手順#
1.S3バケットの作成と設定#
Info
以下の作業はログアカウントで実行します
1.ログアカウントの S3 にアクセスします。
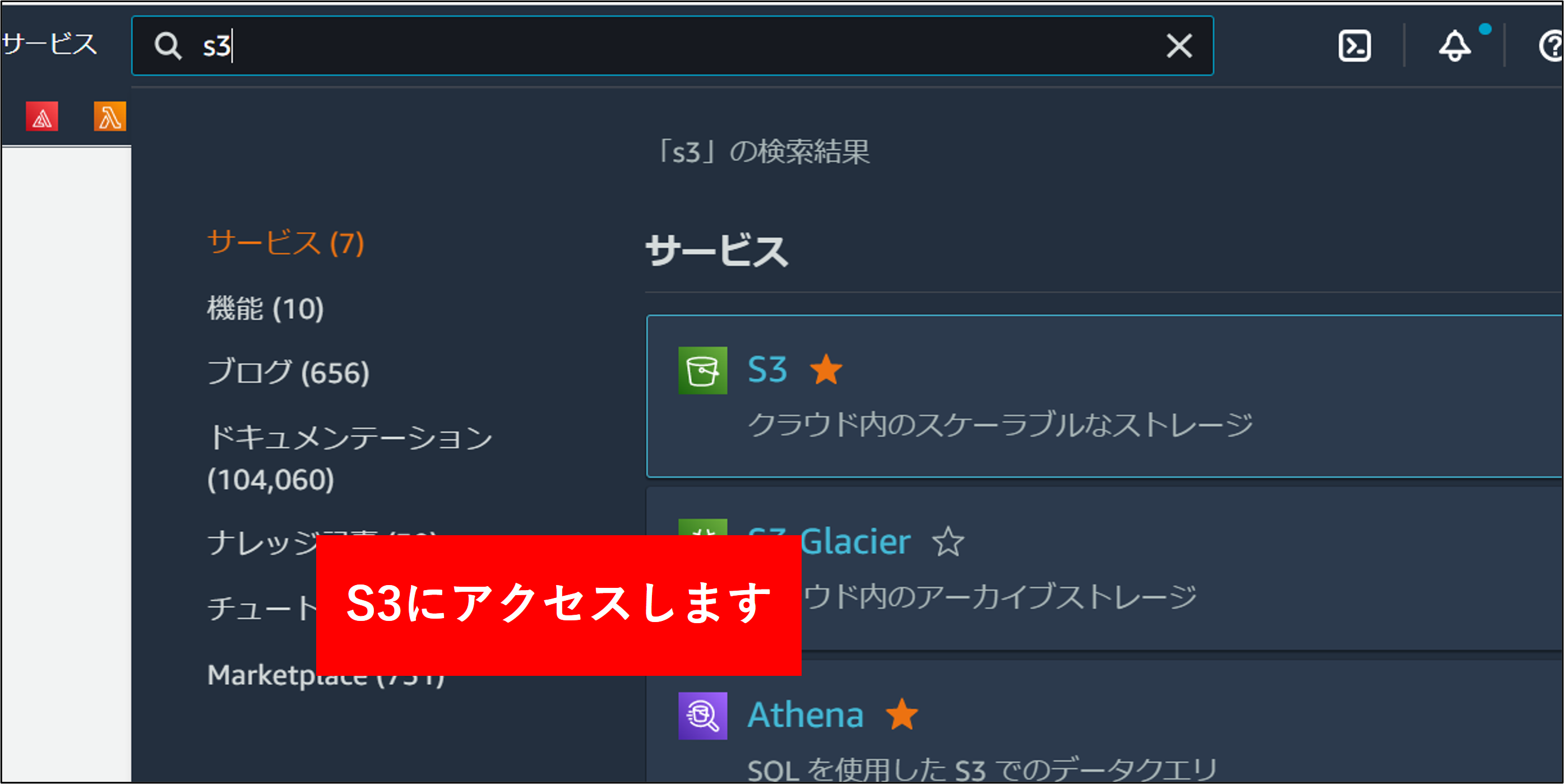
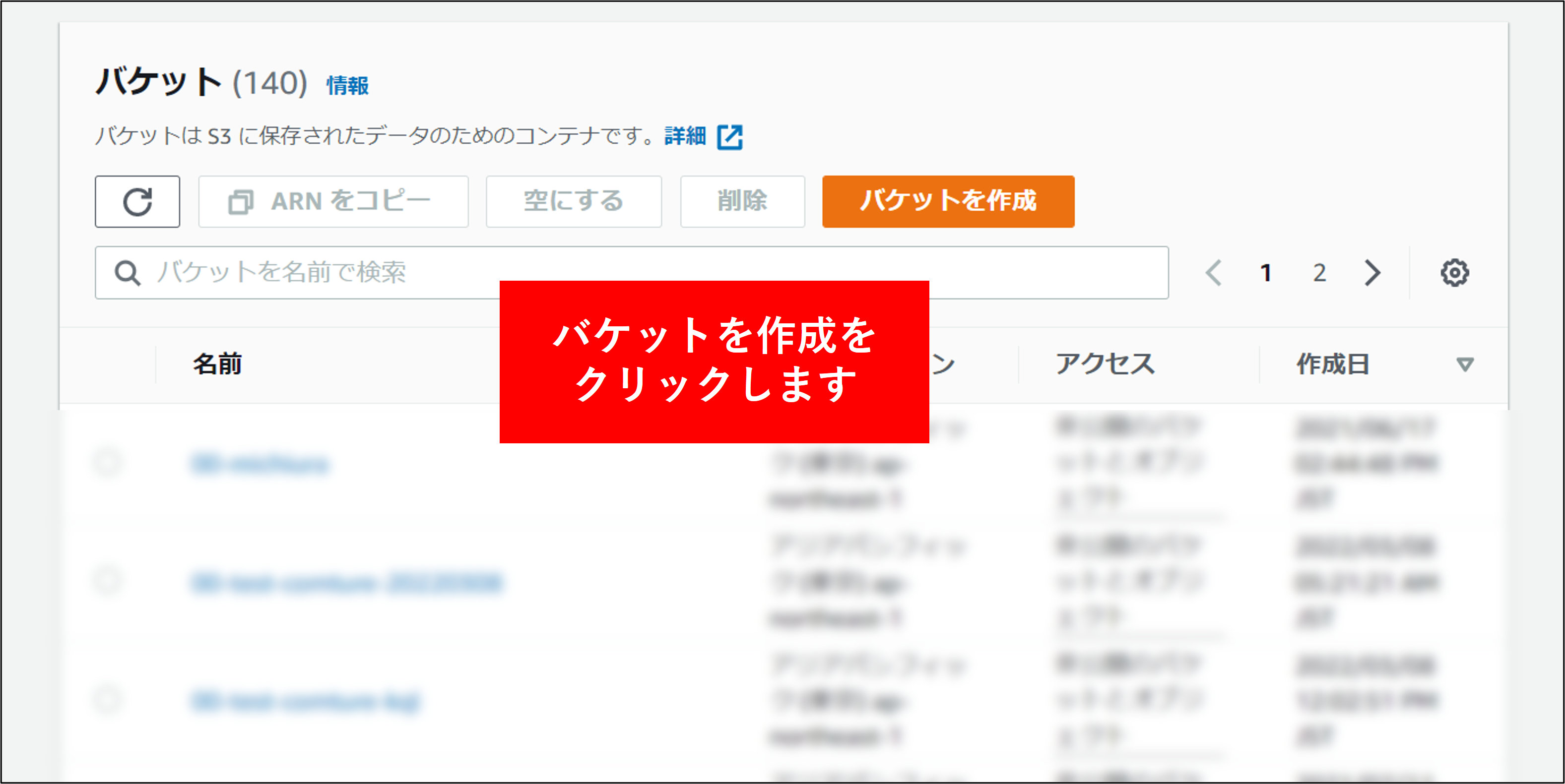
2.S3の画面で バケットを作成する をクリックします。
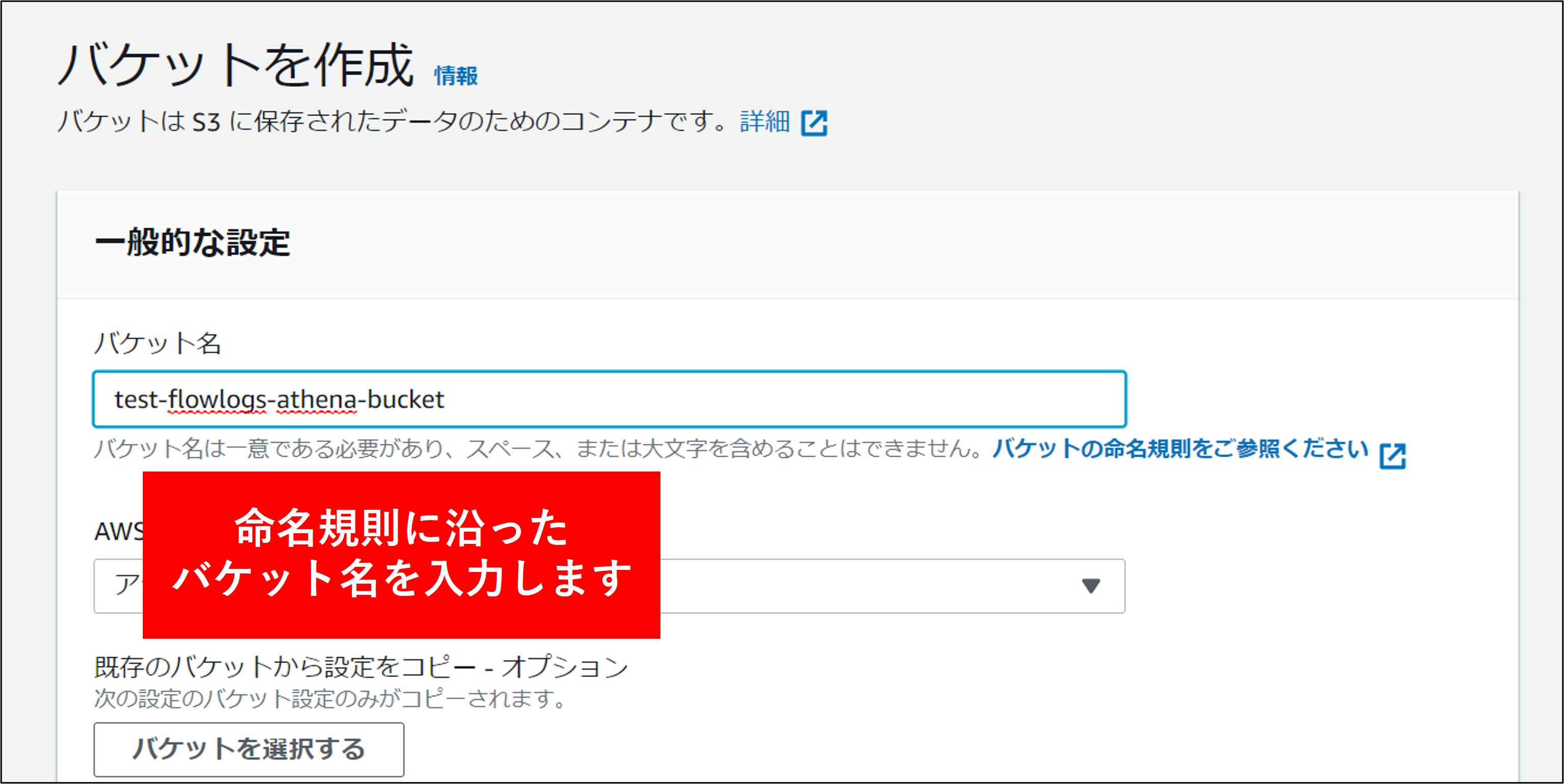
3.自組織の命名規則に沿ったバケット名を指定し、バケットを作成 をクリックします。
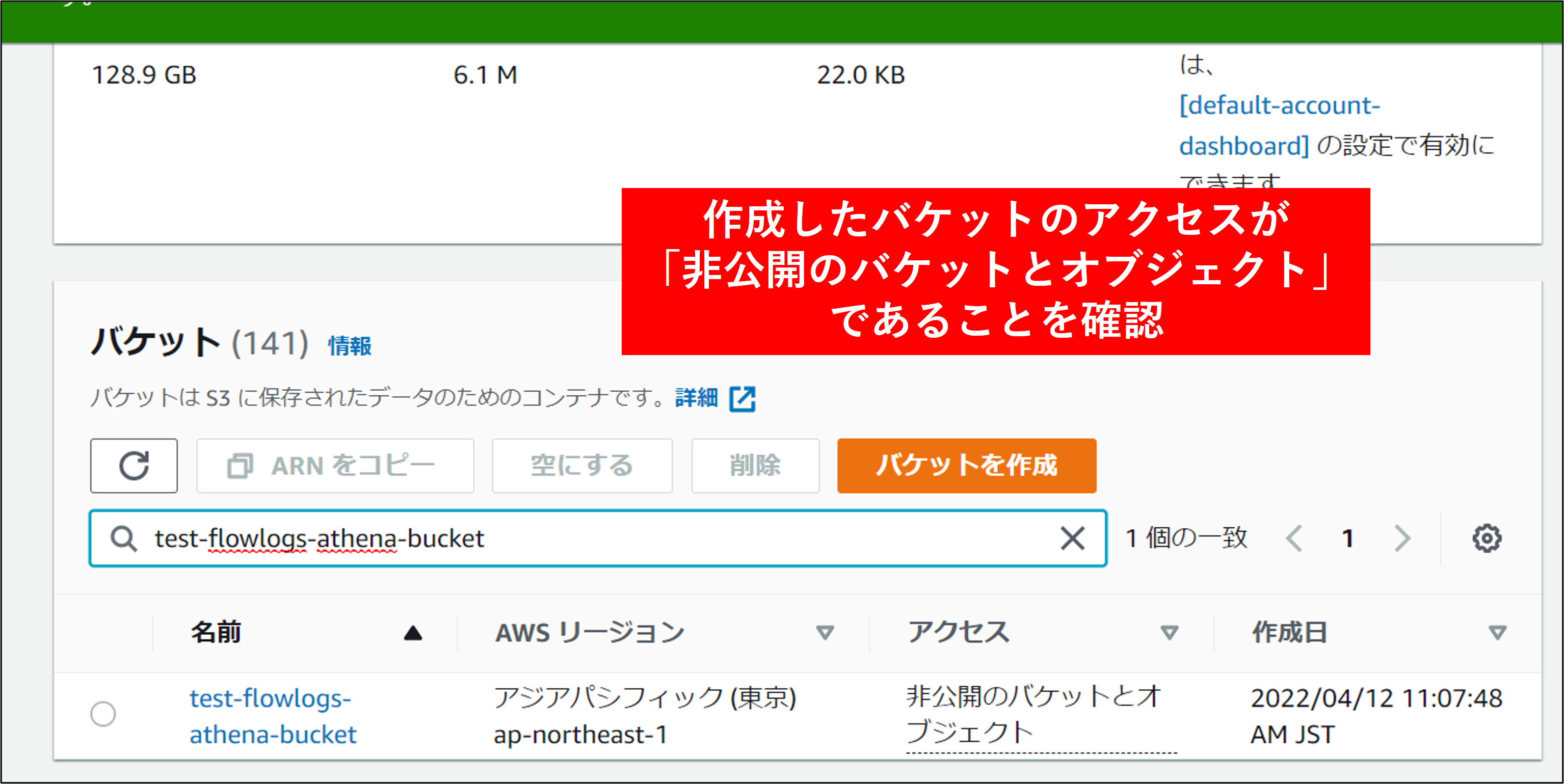
4.バケットが作成されます。アクセスが 非公開 になっていることを確認します。
Note
パブリックアクセスをすべてブロック がチェックされていることを確認してください。
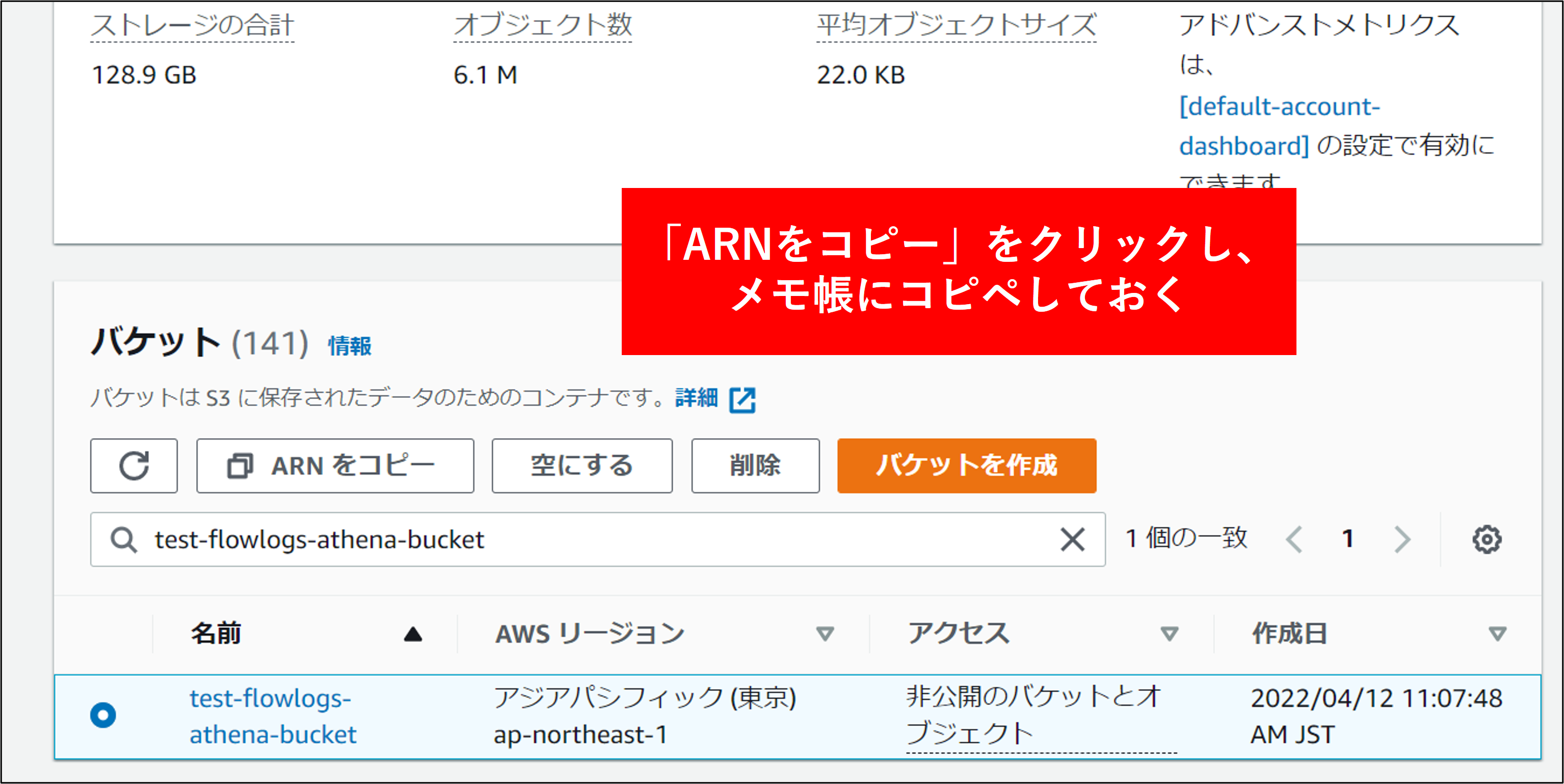
5.バケット作成後画面上部の ARN をコピー をクリックし、メモ帳に貼り付けておきます。
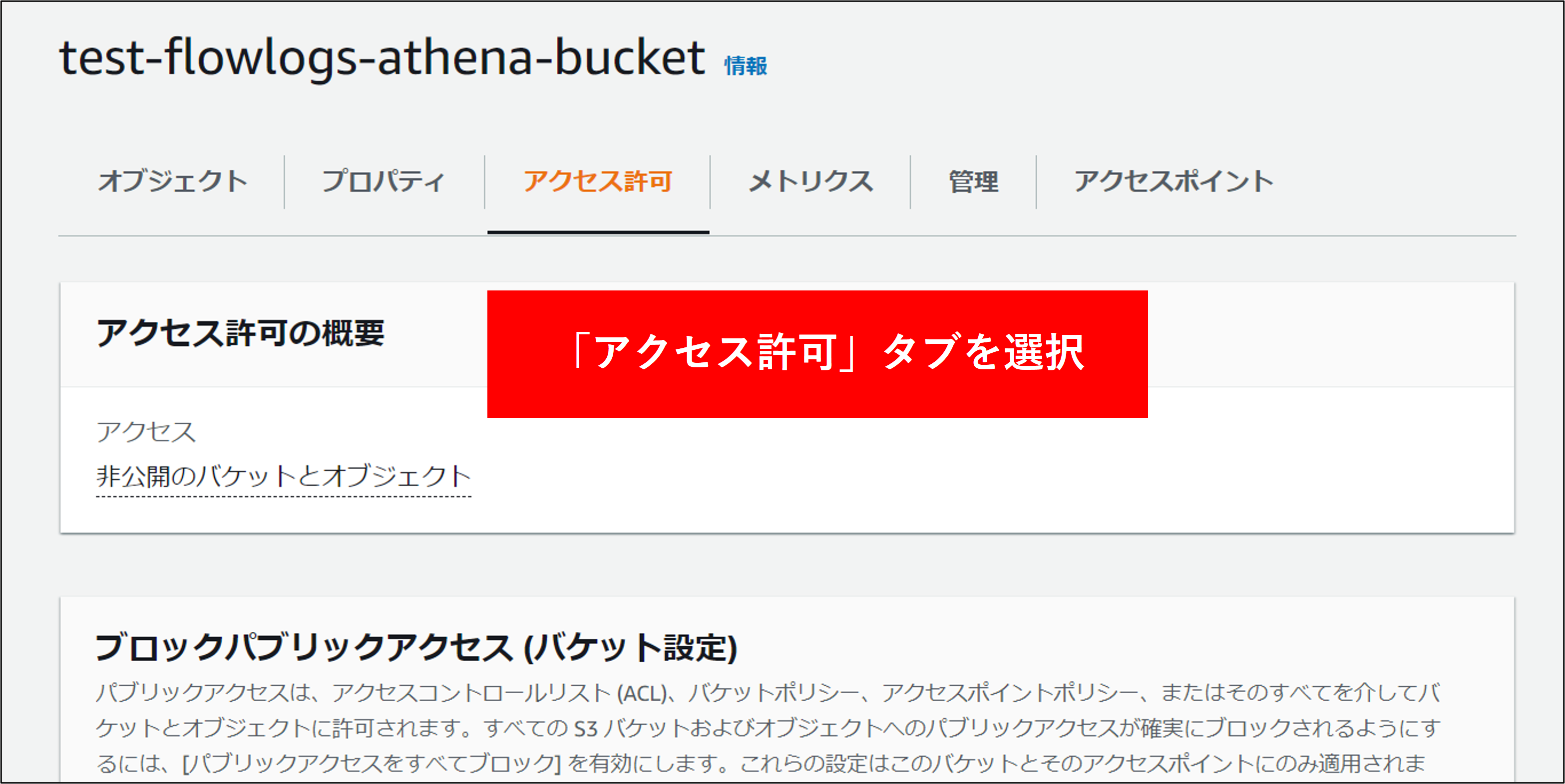
6.最後にバケットポリシーを設定します。これはログアカウント以外からこのバケットにアクセスを許可するためのものです。対象のバケットをクリックし アクセス許可 タブをクリックします。バケットポリシーの編集を行います。
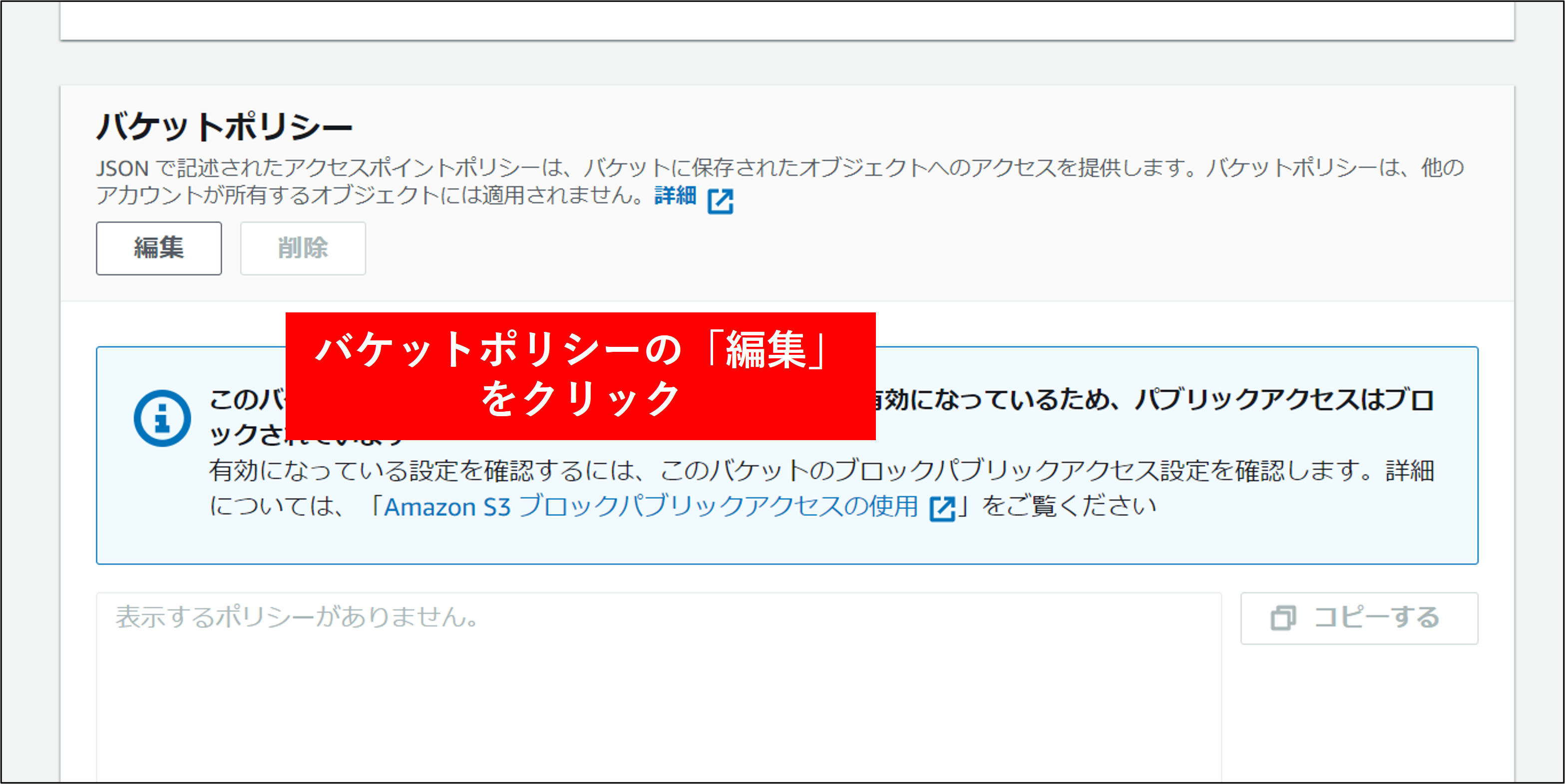
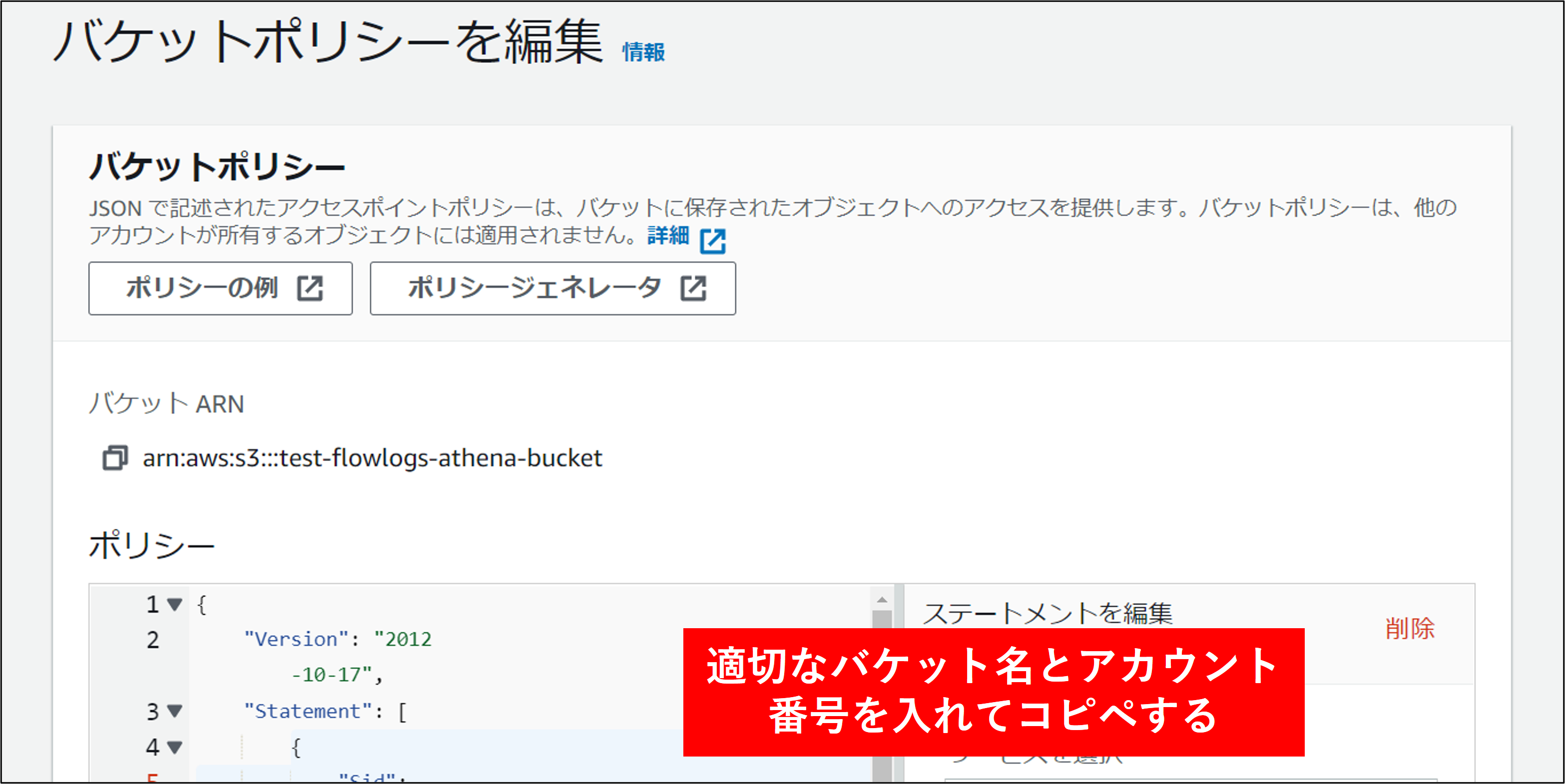
設定するポリシーは以下の通りです。本ポリシーは AWS CloudTrail、AWS Config にも対応します。★部分を修正してバケットポリシーとして構成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSConsolidatedLogs",
"Effect": "Allow",
"Principal": {
"Service": [
"config.amazonaws.com",
"cloudtrail.amazonaws.com",
"delivery.logs.amazonaws.com"
]
},
"Action": "s3:GetBucketAcl",
★"Resource": "arn:aws:s3:::your_bucket_name"
},
{
"Sid": "AWSConsolidatedLogs",
"Effect": "Allow",
"Principal": {
"Service": [
"config.amazonaws.com",
"cloudtrail.amazonaws.com",
"delivery.logs.amazonaws.com"
]
},
"Action": "s3:PutObject",
"Resource": [
★"arn:aws:s3:::your_bucket_name/AWSLogs/aws_accountNo/*",
★"arn:aws:s3:::your_bucket_name/AWSLogs/aws_accountNo/Config/*"
],
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
2.VPC Flowlogsの設定#
Info
本設定はVPC FlowLogsを取得する各リソースアカウントで実施します
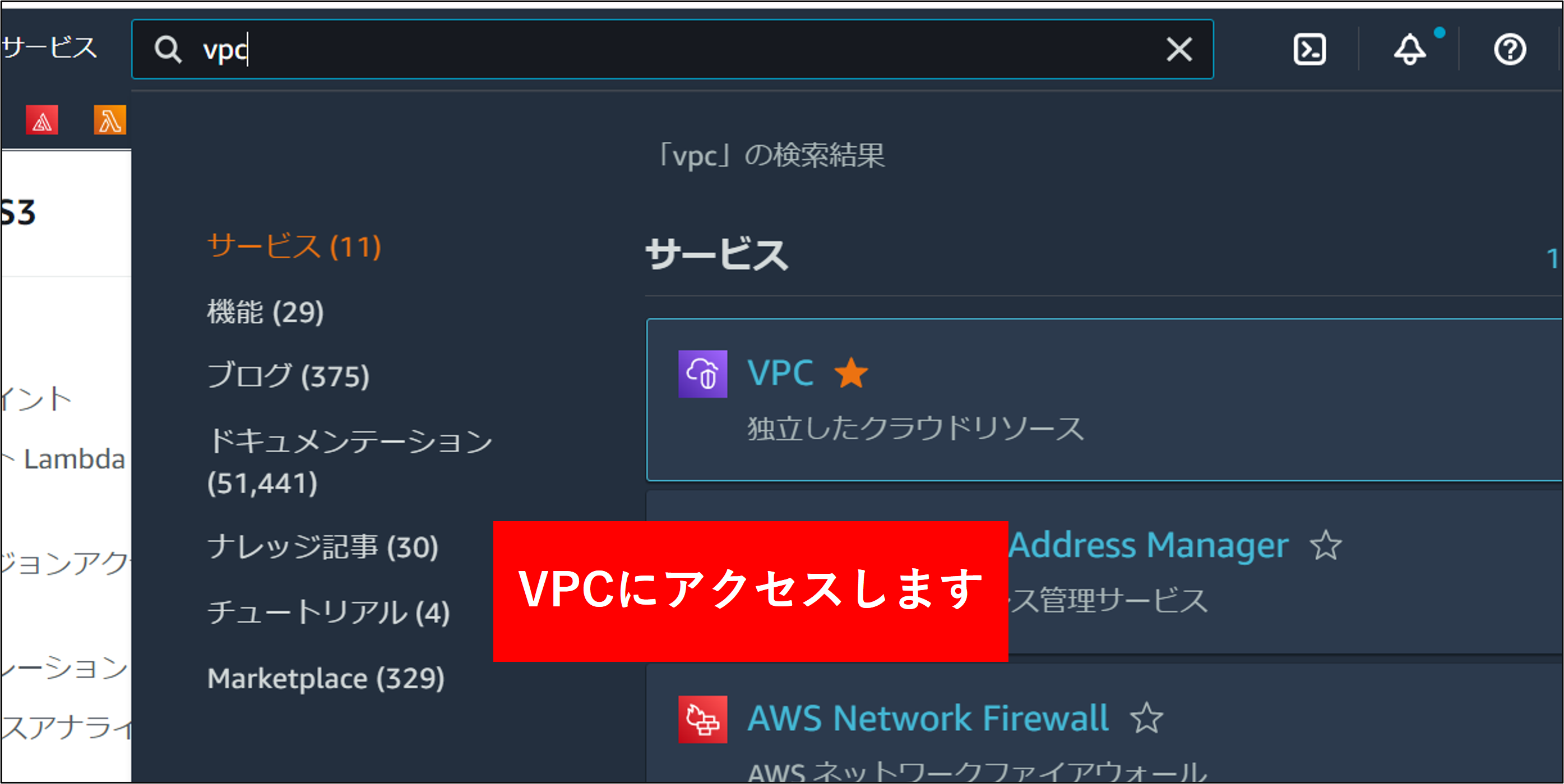
1.VPCのメニューを開き、フローログ取得対象のVPCを選択し、フローログの作成 をクリックします。
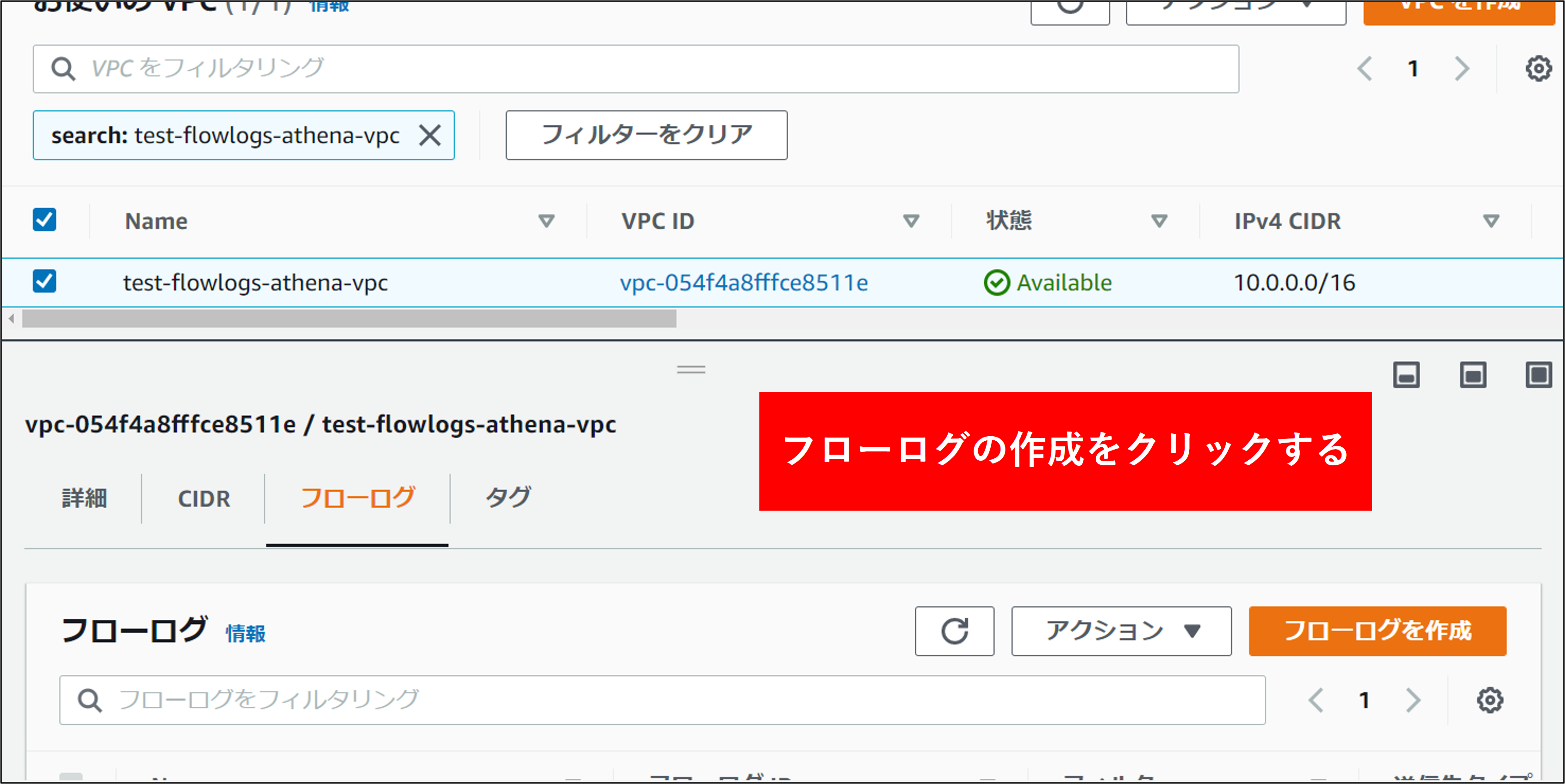
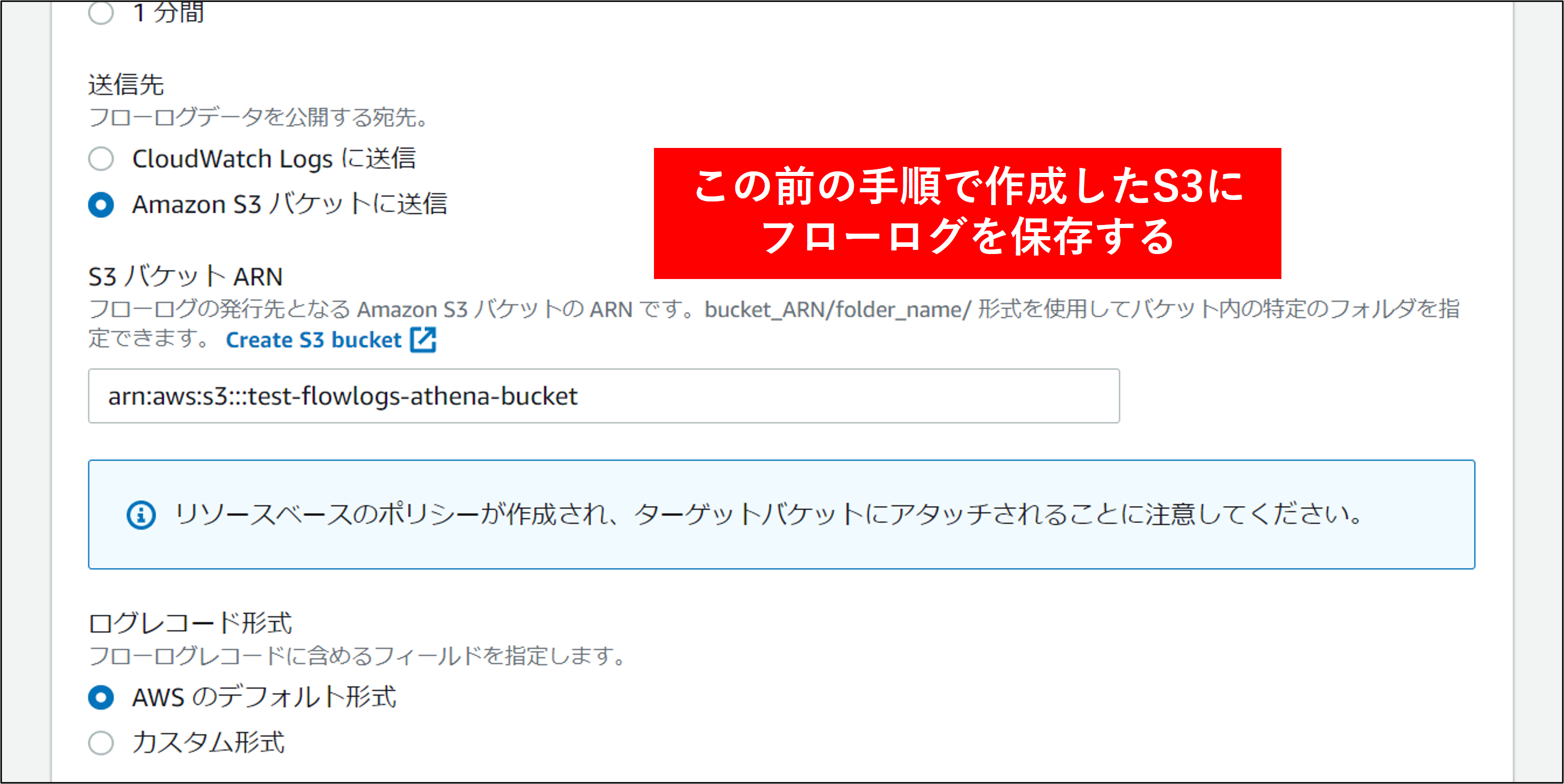
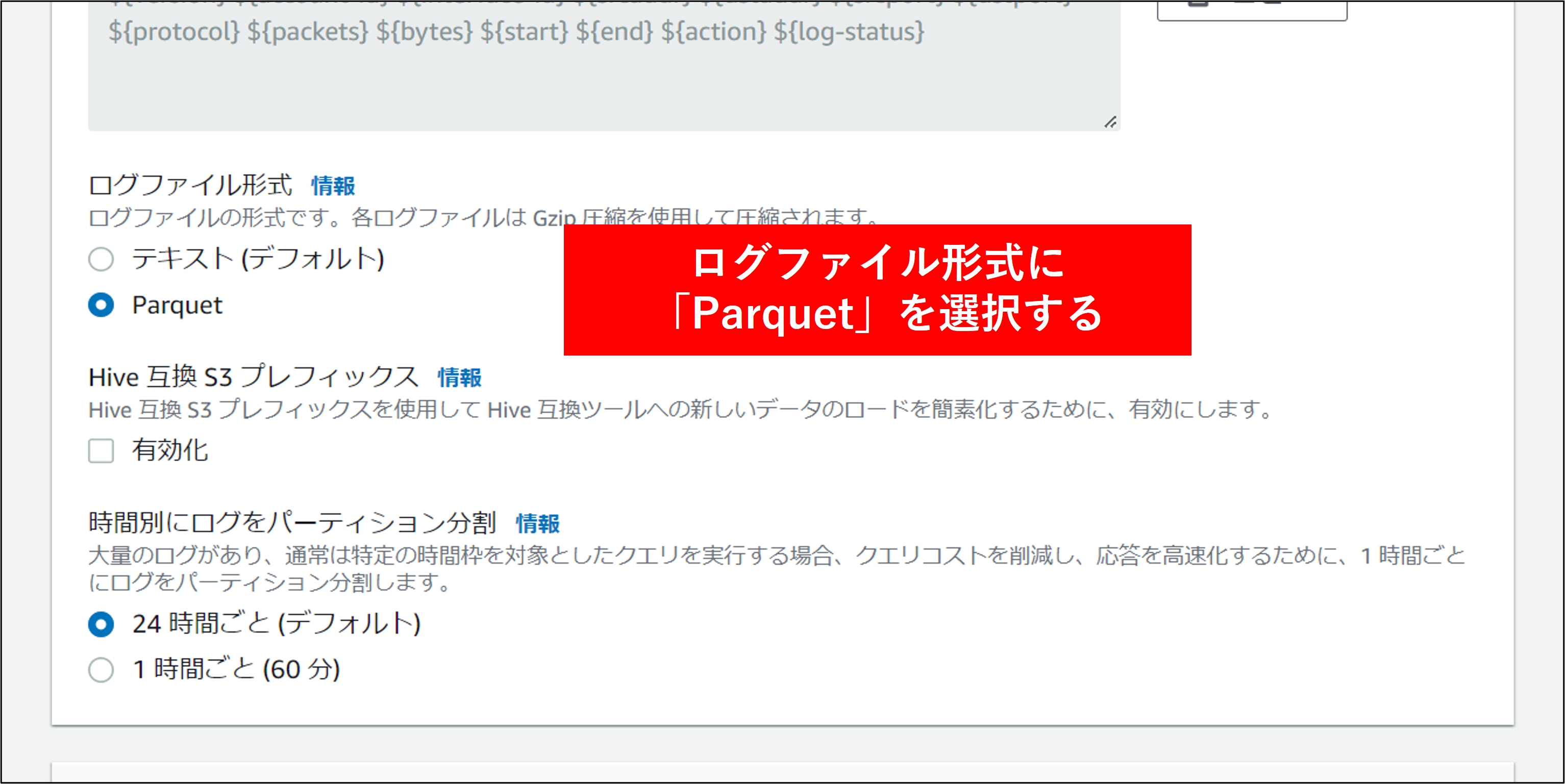
2.フローログの作成 画面で各項目を指定し、フローログを作成 をクリックします。
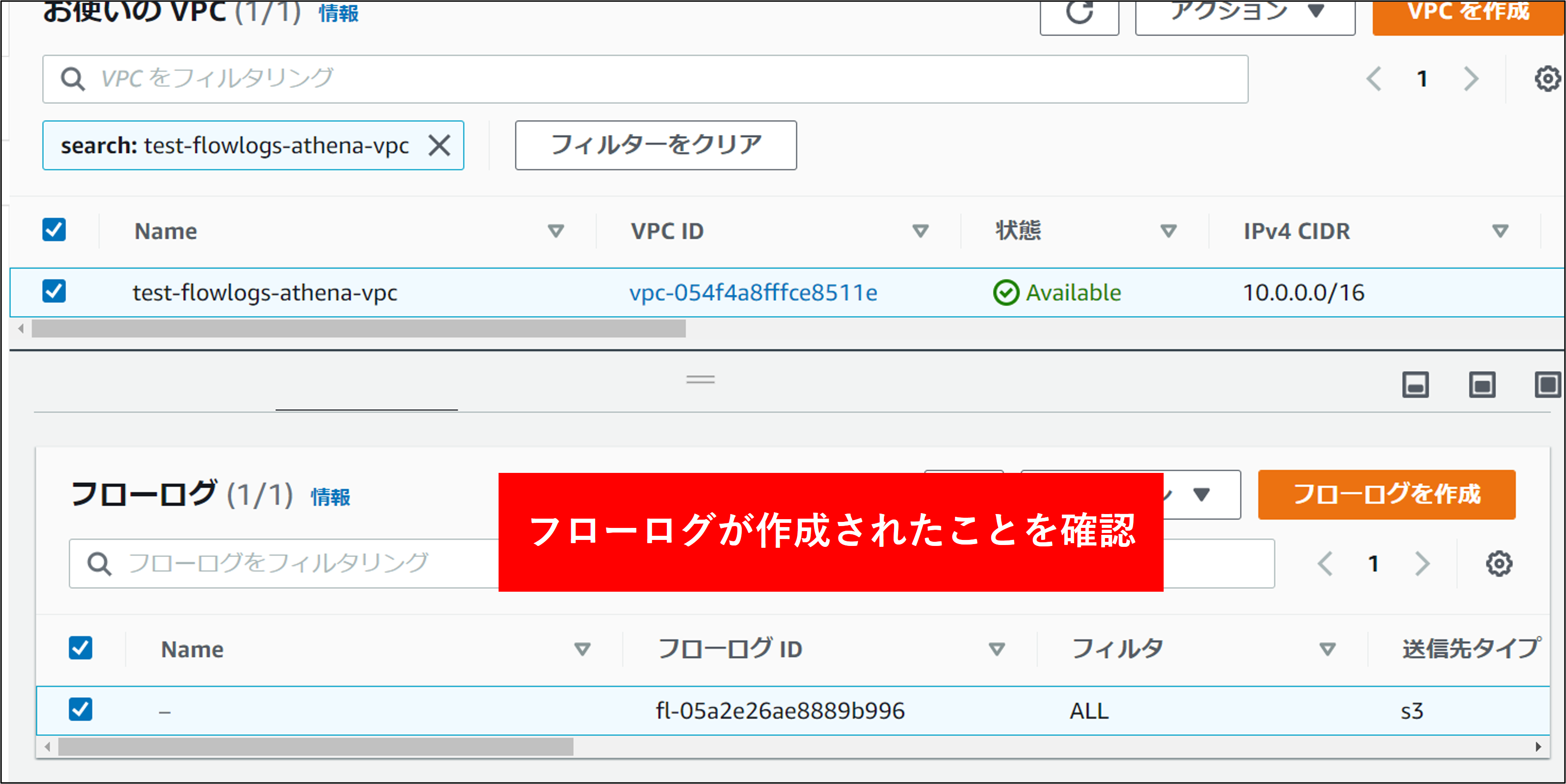
3.VPC を選択し、下図のフローログのタブからフローログが作成されていることを確認します。
3.Athenaからクエリが実行できるようにする#
Info
以下の作業はログアカウントで実行します
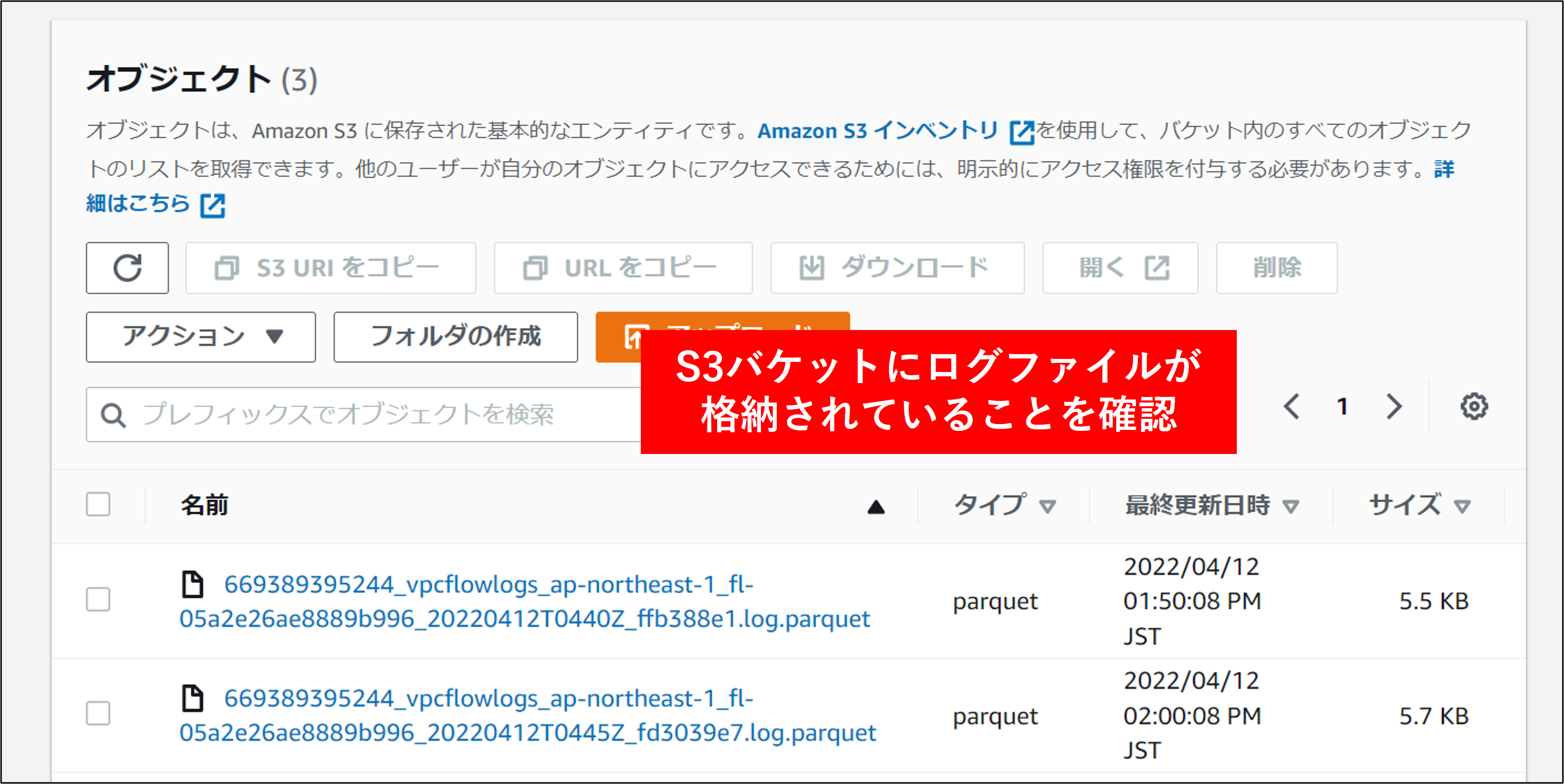
1.最初に ログアカウントの S3 に指定通りログが保存されていることを確認します。 S3 にアクセスし、設定済みのログを確認します。以下のように vpcflowlogs フォルダが作成され、parquet形式のログが保存されていることを確認します。
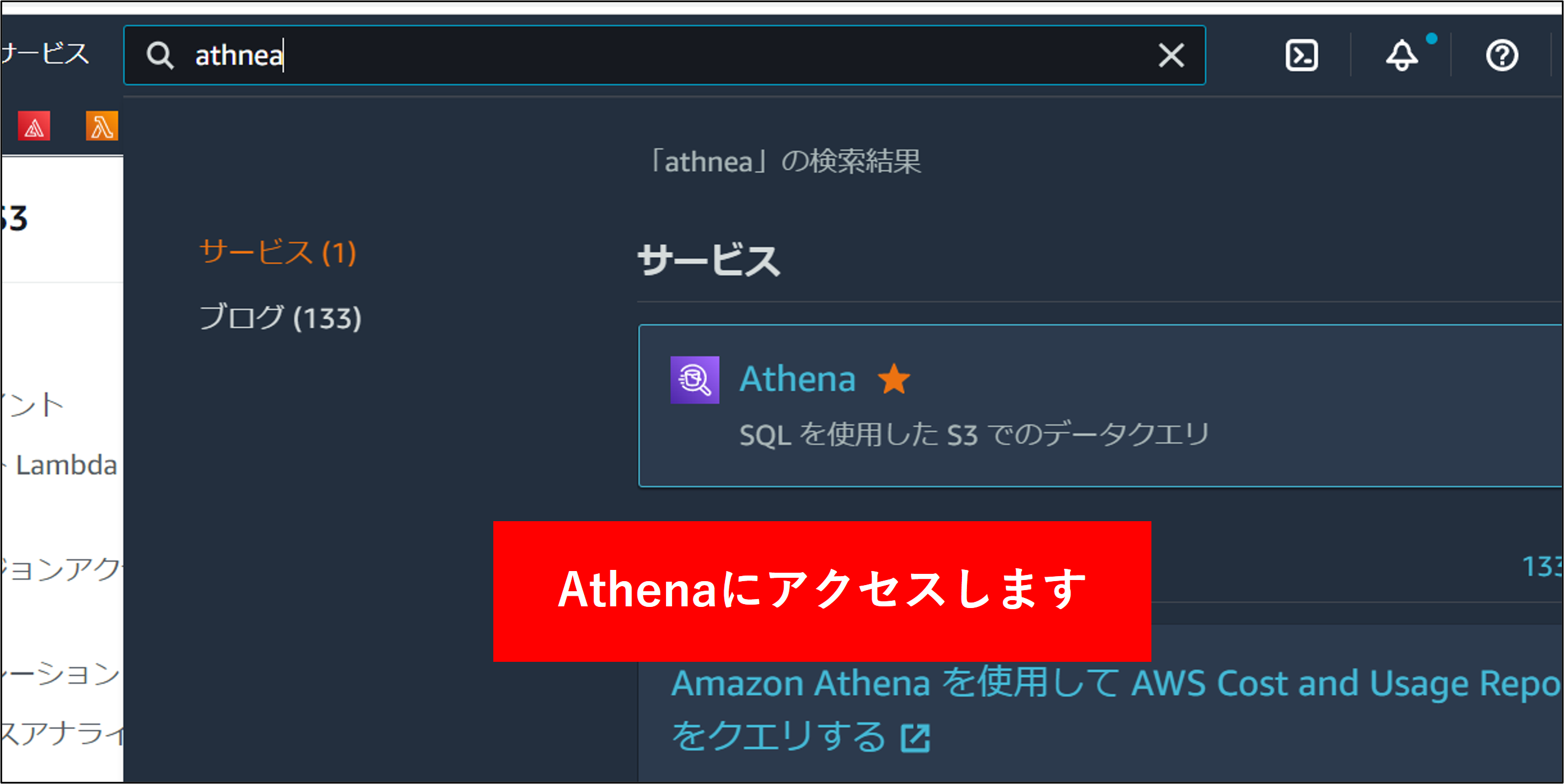
2.AWS 管理コンソールから Athena へアクセスします。
3.Athena の管理コンソールから DDL を定義します。これにより FlowLogs のテーブルが作成されます。定義にあたっては以下の DDL をコピペして実行します。
Info
行頭のテーブル名および LOCATION 部分は適切な名称に修正してください。
Attention
データベース、テーブル、および列の名前には、小文字、数字、アンダースコア文字のみを使用できます。 ハイフンなどを利用することはできないため注意してください。
CREATE EXTERNAL TABLE IF NOT EXISTS vpc_flow_logs_組織名 (
`version` int,
`account_id` string,
`interface_id` string,
`srcaddr` string,
`dstaddr` string,
`srcport` int,
`dstport` int,
`protocol` bigint,
`packets` bigint,
`bytes` bigint,
`start` bigint,
`end` bigint,
`action` string,
`log_status` string,
`vpc_id` string,
`subnet_id` string,
`instance_id` string,
`tcp_flags` int,
`type` string,
`pkt_srcaddr` string,
`pkt_dstaddr` string,
`az_id` string,
`sublocation_type` string,
`sublocation_id` string,
`pkt_src_aws_service` string,
`pkt_dst_aws_service` string,
`flow_direction` string,
`traffic_path` int
)
PARTITIONED BY (`date` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://your_log_bucket/prefix/AWSLogs/{subscribe_account_id}/vpcflowlogs/{region_code}/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.date.type" = "date",
"projection.date.range" = "NOW-1DAYS,NOW",
"projection.date.format" = "yyyy/MM/dd",
"storage.location.template" = "s3://your_log_bucket/prefix/AWSLogs/{subscribe_account_id}/vpcflowlogs/{region_code}/${date}/"
)
Info
"projection.date.range" = "NOW-1DAYS,NOW"で日付の範囲を指定しています。
これは昨日から今日までの範囲を指定しています。
複数のアカウントを指定したい場合は下記のように記述することができます。
CREATE EXTERNAL TABLE IF NOT EXISTS vpc_flow_logs_組織名 (
`version` int,
`account_id` string,
`interface_id` string,
`srcaddr` string,
`dstaddr` string,
`srcport` int,
`dstport` int,
`protocol` bigint,
`packets` bigint,
`bytes` bigint,
`start` bigint,
`end` bigint,
`action` string,
`log_status` string,
`vpc_id` string,
`subnet_id` string,
`instance_id` string,
`tcp_flags` int,
`type` string,
`pkt_srcaddr` string,
`pkt_dstaddr` string,
`az_id` string,
`sublocation_type` string,
`sublocation_id` string,
`pkt_src_aws_service` string,
`pkt_dst_aws_service` string,
`flow_direction` string,
`traffic_path` int
)
PARTITIONED BY (`account` string,`date` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://your_log_bucket/prefix/AWSLogs/{subscribe_account_id}/vpcflowlogs/{region_code}/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.account.type" = "enum",
"projection.account.values" = "111111111111,222222222222",
"projection.date.type" = "date",
"projection.date.range" = "NOW-1DAYS,NOW",
"projection.date.format" = "yyyy/MM/dd",
"storage.location.template" = "s3://test-flowlogs-athena-bucket/AWSLogs/${account}/vpcflowlogs/ap-northeast-1/${date}/"
)
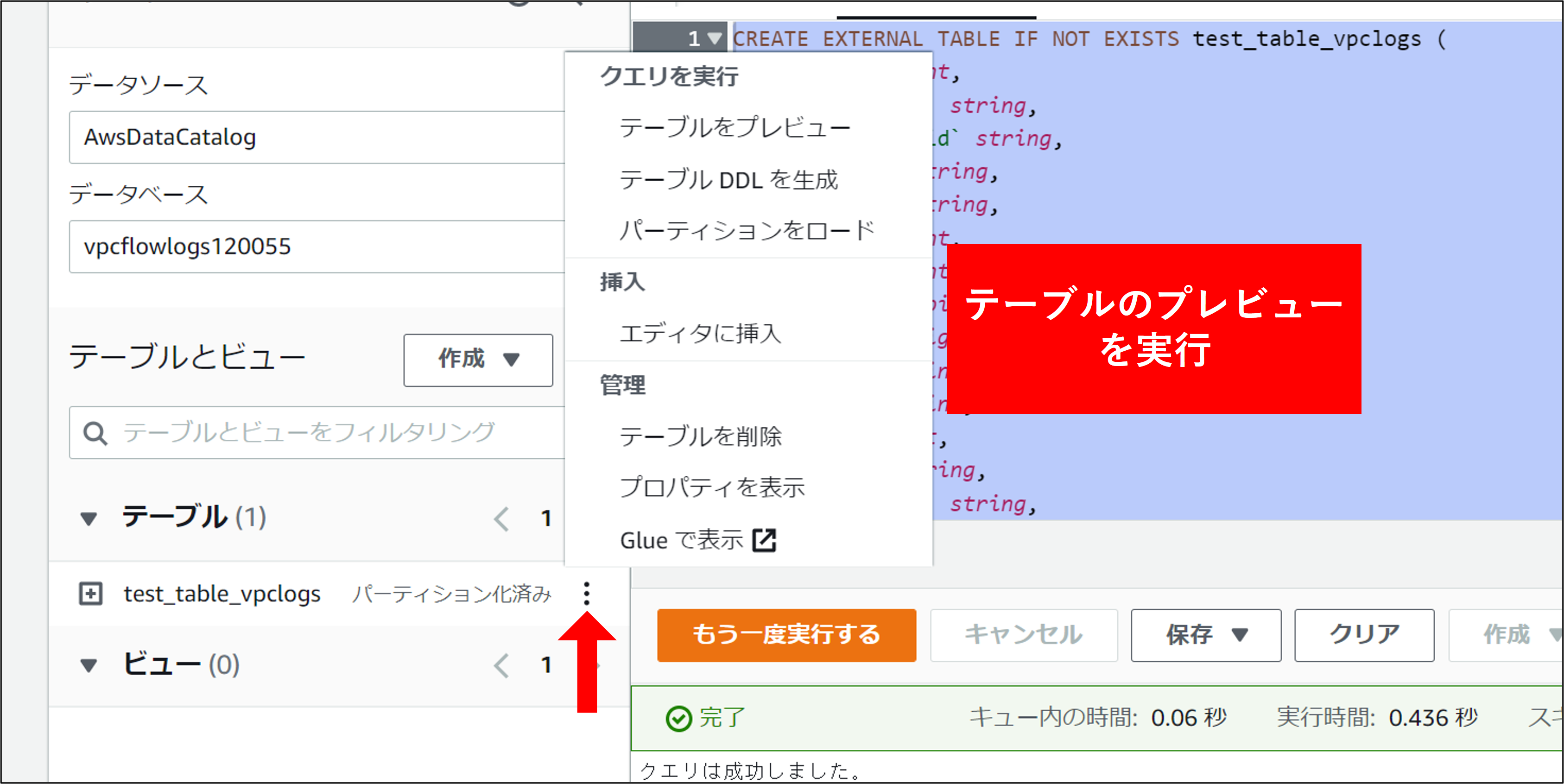
4.テスト用のクエリを実行します。画面左側のテーブル一覧から、赤矢印部分をクリックし テーブルのプレビュー をクリックします。
5.実際に状況を抽出する FlowLogs のクエリを実行してみます。以下は、複数アカウントある場合にアカウントIDで抽出した例です。
Attention
100万行を超過するとExcelで確認できないため注意してください
select
format_datetime(from_unixtime("start", 9, 0),'yyyy-MM-dd HH:mm:ss') AS starttime_jst,
format_datetime(from_unixtime("end", 9, 0),'yyyy-MM-dd HH:mm:ss') AS endtime_jst,
srcaddr,
dstaddr,
dstport,
packets,
bytes
from vpc_flow_logs_組織名
where 1 = 1
AND log_status = 'OK'
AND account_id = '111111111111'
ORDER by starttime_jst
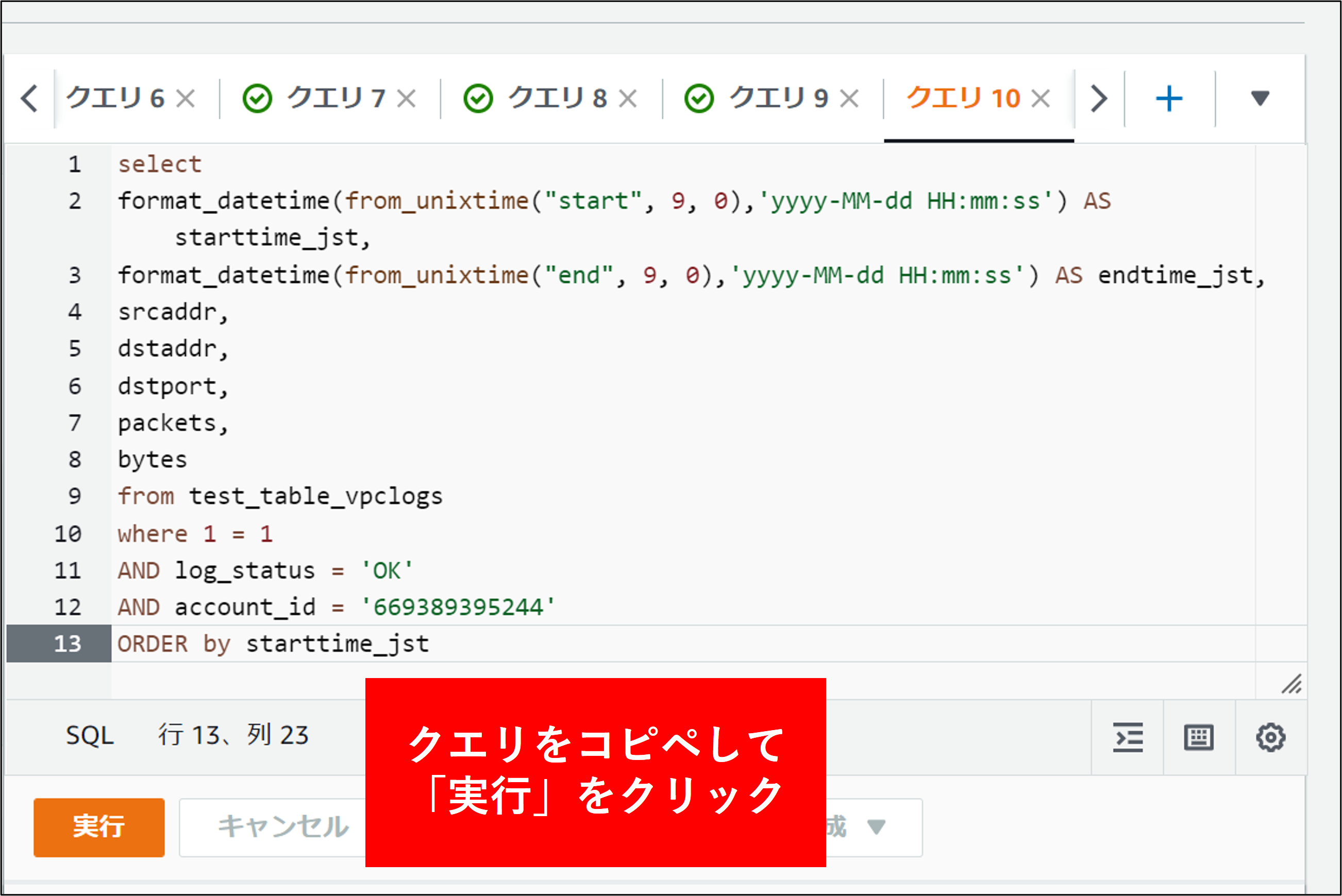
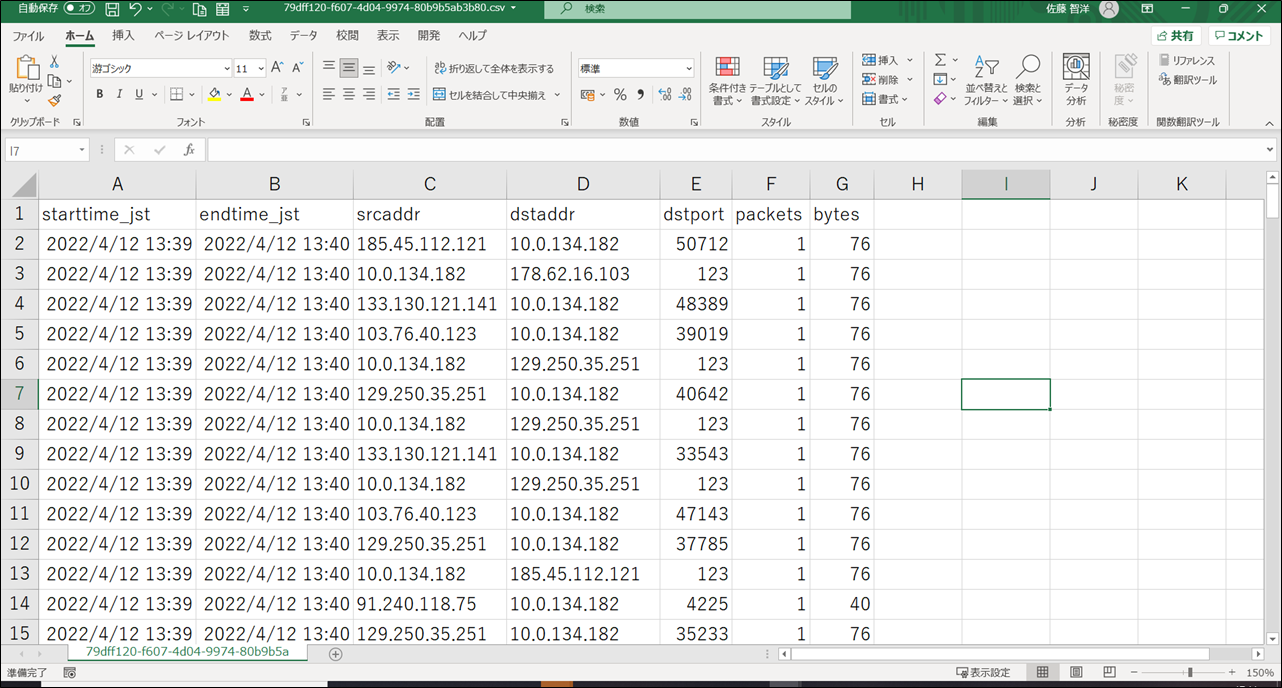
6.結果が表示されます。結果を CSV で出力するには、赤矢印部分をクリックします。
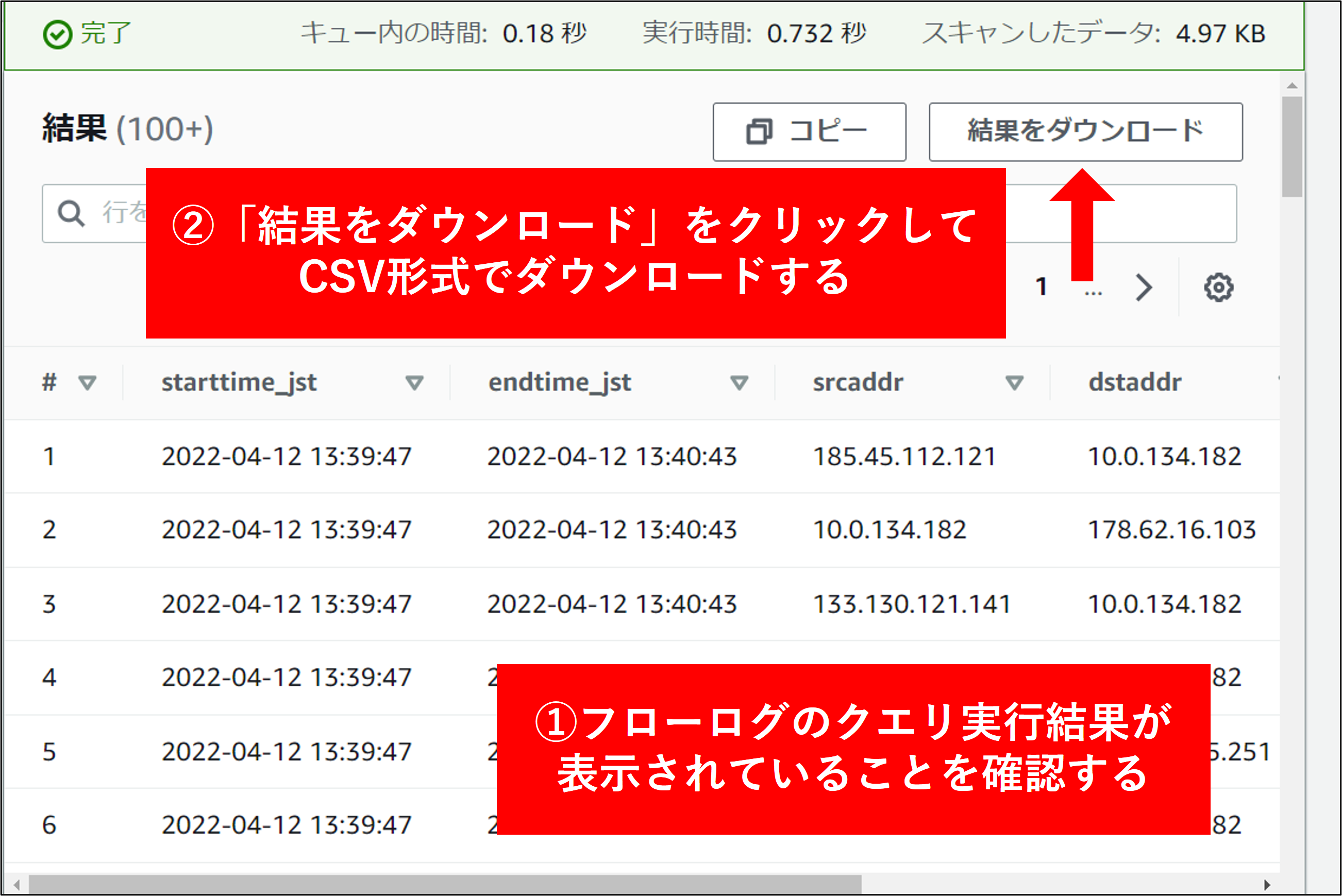
7.ダウンロードされた結果を Excel で確認します。