CloudTrail を S3 に保存しAthenaで抽出する方法#
概要#
本資料は CloudTrail のログを特定ログアカウントの S3 バケットに格納し、Athena にて トラフィックを分析する手順を記載します。
- 1.S3バケットの作成と設定
- 2.CloudTrail の設定
- 3.Amazon Athenaでの取り込み設定と動作確認
手順#
1.S3バケットの作成と設定#
Info
以下の作業はログアカウントで実行します
1.ログアカウントの S3 にアクセスします。
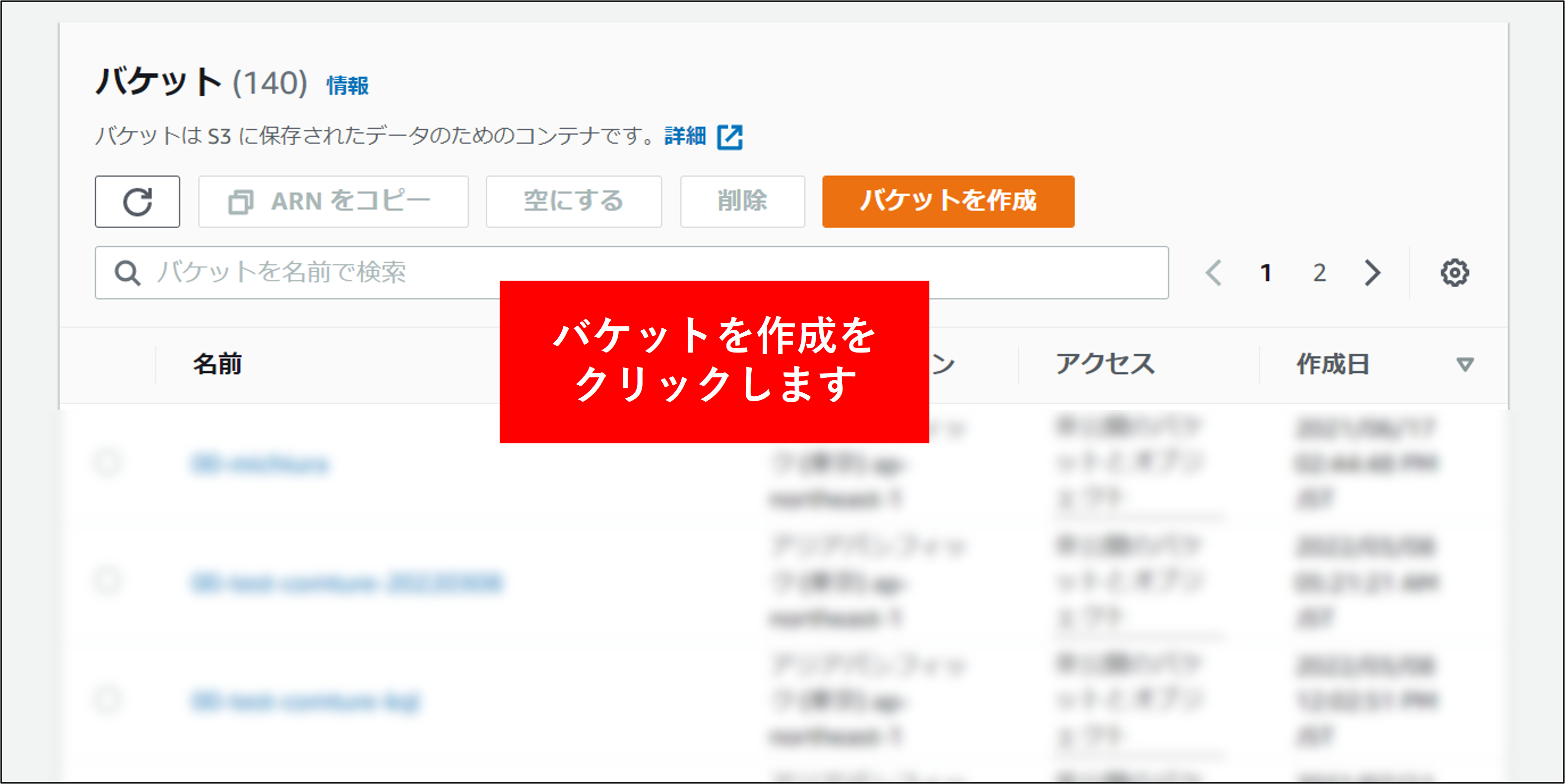
2.S3の画面で バケットを作成する をクリックします。
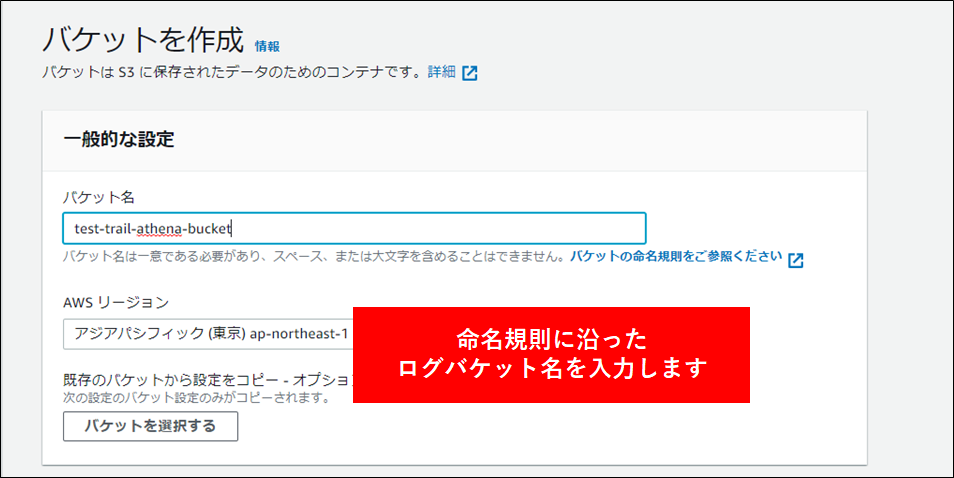
3.自組織の命名規則に沿ったバケット名を指定し、バケットを作成 をクリックします。
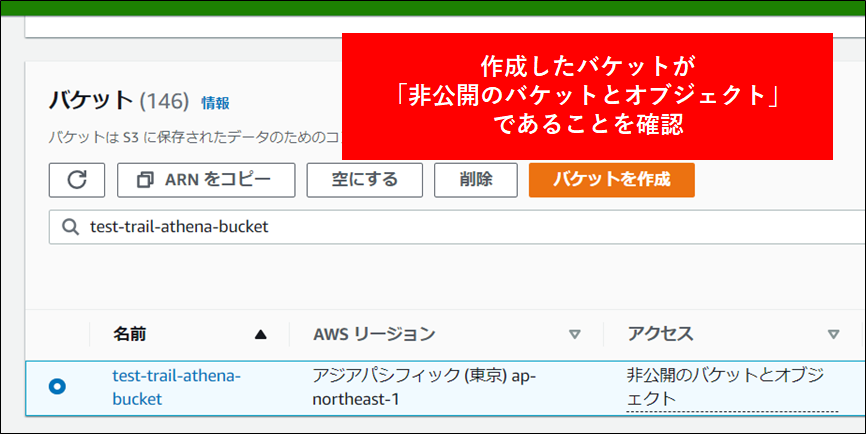
4.バケットが作成されます。アクセスが 非公開 になっていることを確認します。
Note
パブリックアクセスをすべてブロック がチェックされていることを確認してください。
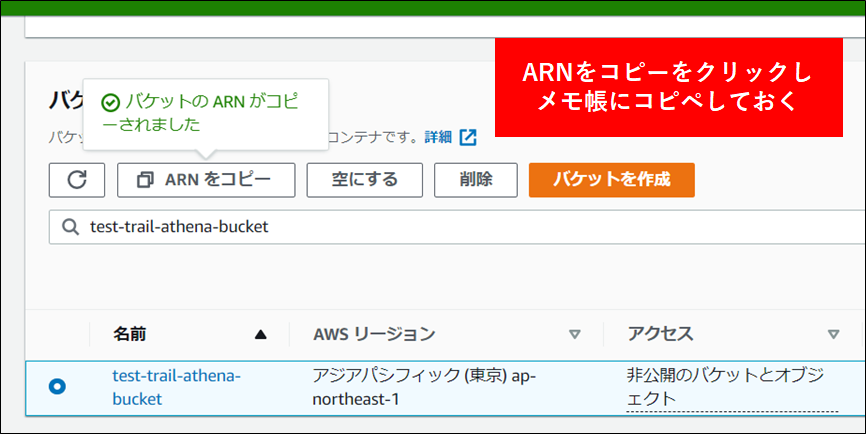
5.バケット作成後画面上部の ARN をコピー をクリックし、メモ帳に貼り付けておきます。
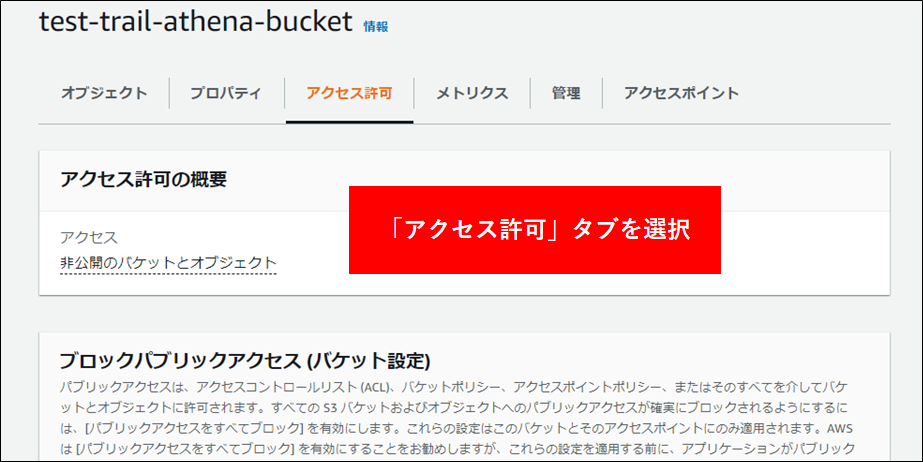
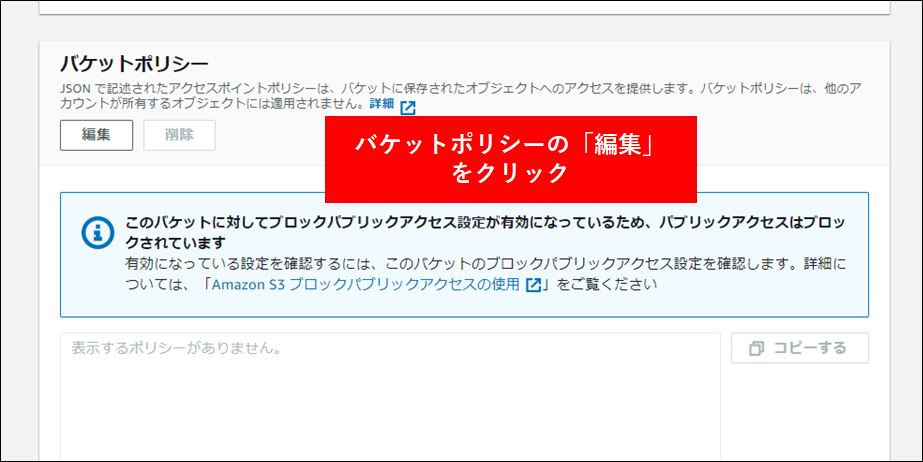
6.最後にバケットポリシーを設定します。これはログアカウント以外からこのバケットにアクセスを許可するためのものです。対象のバケットをクリックし アクセス許可 タブをクリックします。バケットポリシーの編集を行います。
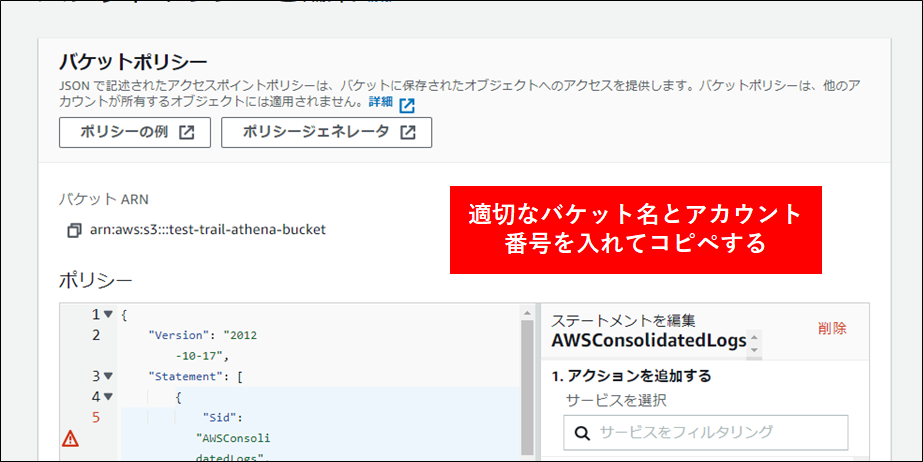
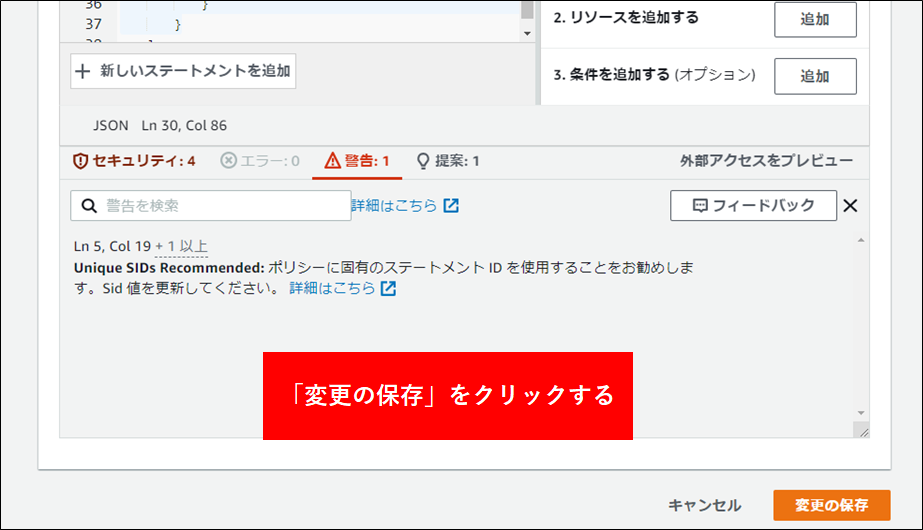
設定するポリシーは以下の通りです。本ポリシーは AWS CloudTrail、AWS Config にも対応します。★部分を修正してバケットポリシーとして構成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSConsolidatedLogs",
"Effect": "Allow",
"Principal": {
"Service": [
"config.amazonaws.com",
"cloudtrail.amazonaws.com",
"delivery.logs.amazonaws.com"
]
},
"Action": "s3:GetBucketAcl",
★"Resource": "arn:aws:s3:::your_bucket_name"
},
{
"Sid": "AWSConsolidatedLogs",
"Effect": "Allow",
"Principal": {
"Service": [
"config.amazonaws.com",
"cloudtrail.amazonaws.com",
"delivery.logs.amazonaws.com"
]
},
"Action": "s3:PutObject",
"Resource": [
★"arn:aws:s3:::your_bucket_name/AWSLogs/aws_accountNo/*",
★"arn:aws:s3:::your_bucket_name/AWSLogs/aws_accountNo/Config/*"
],
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control"
}
}
}
]
}
2.Cloudtrail の設定#
Info
本設定は Cloudtrail を取得する各リソースアカウントで実施します
1.AWS 管理コンソールから Cloudtrail にアクセスします。
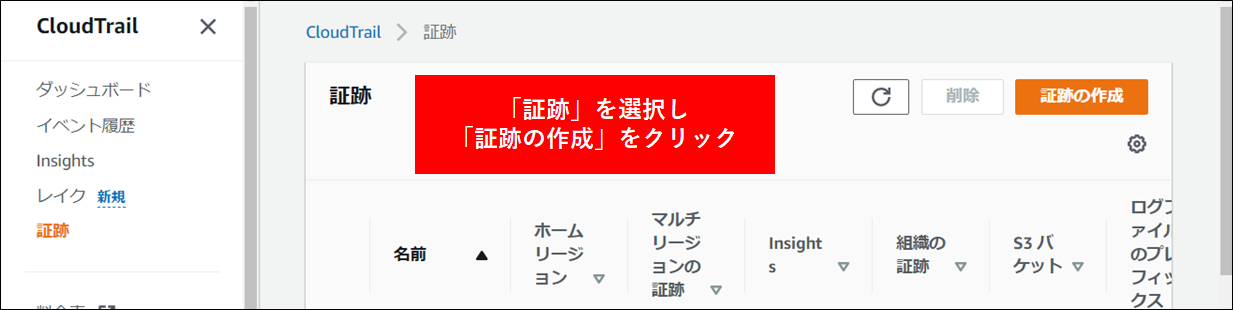
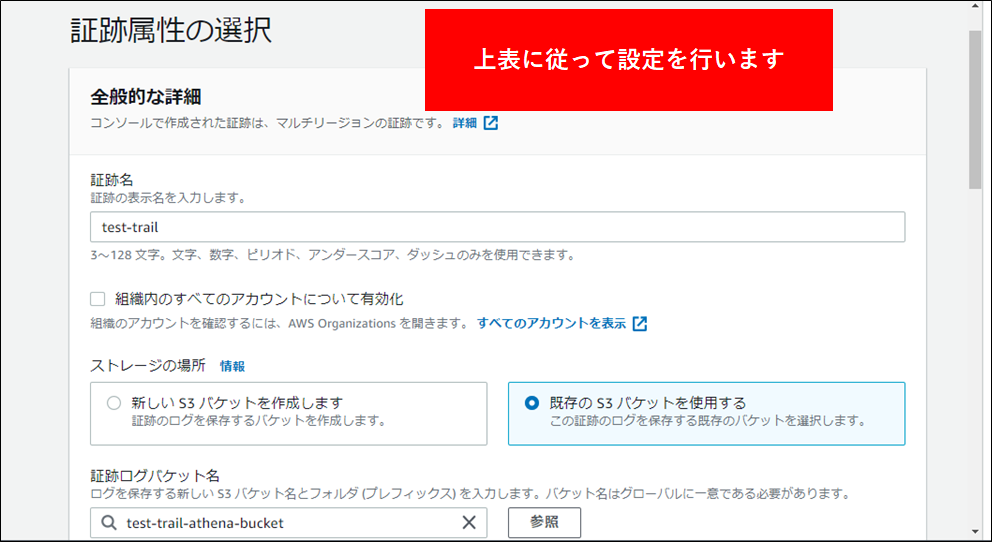
2.CloudTrail を設定して指定のバケットにデータが保存されるようにします。CloudTrailの左側メニューの証跡に移動し証跡の作成をクリックし、CloudTrail のログを記録するための設定を行います。
すでにS3バケットに記録している場合は、本作業は省略して構いません。
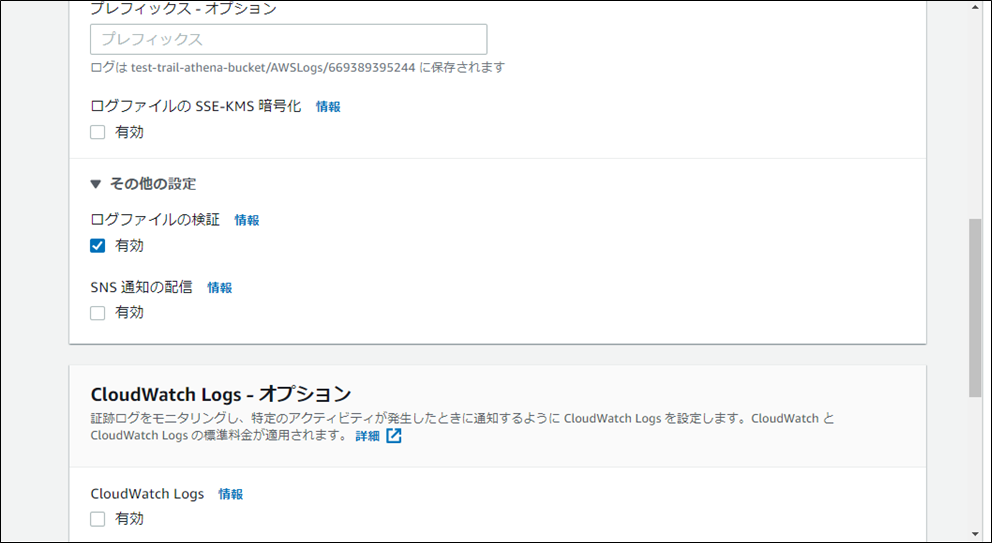
3.証跡を作成する場合は、下表に従って設定を行います。
| 設定項目 | 設定値 | 備考 |
|---|---|---|
| 証跡名 | CloudTrail-アカウント名など | 命名規則に応じて変更します |
| 組織内の全てのアカウントについて有効化 | 無効 | Organizationsを利用している場合は有効にする |
| ストレージの場所 | 既存のS3バケットを使用する | 前もって作成したS3を指定する |
| ログファイルのプレフィクス | 指定しない | |
| SSE-KMSを使用してログファイルを暗号化 | 無効 | |
| ログファイルの検証を有効化しますか | 有効 | |
| SNS通知の配信 | 無効 | |
| CloudWatch Logs | 無効 | |
| タグ | 必要に応じて記入 | 命名規則に応じて変更します |
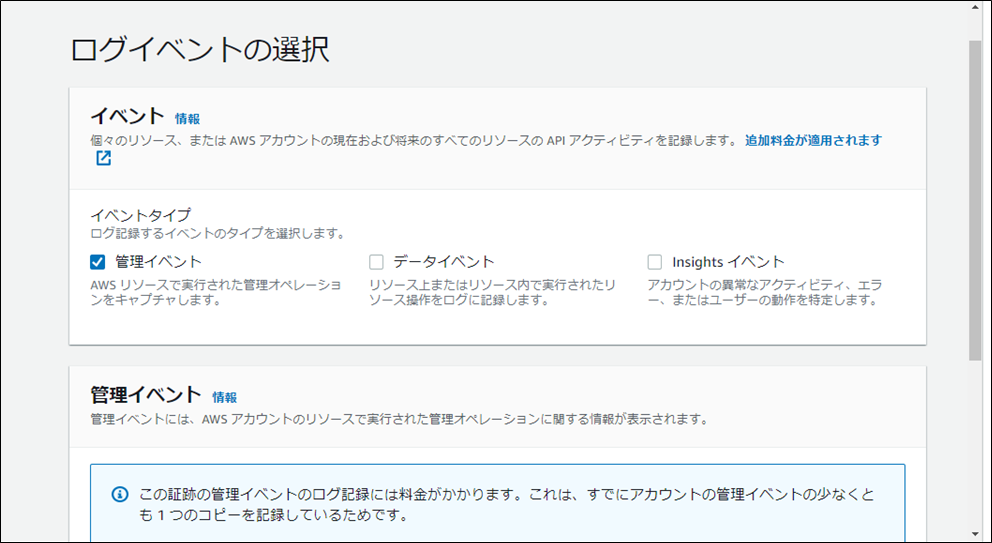
| イベント | 管理イベントを選択する | |
| 管理イベント | 読み取り、書き込みを有効 |
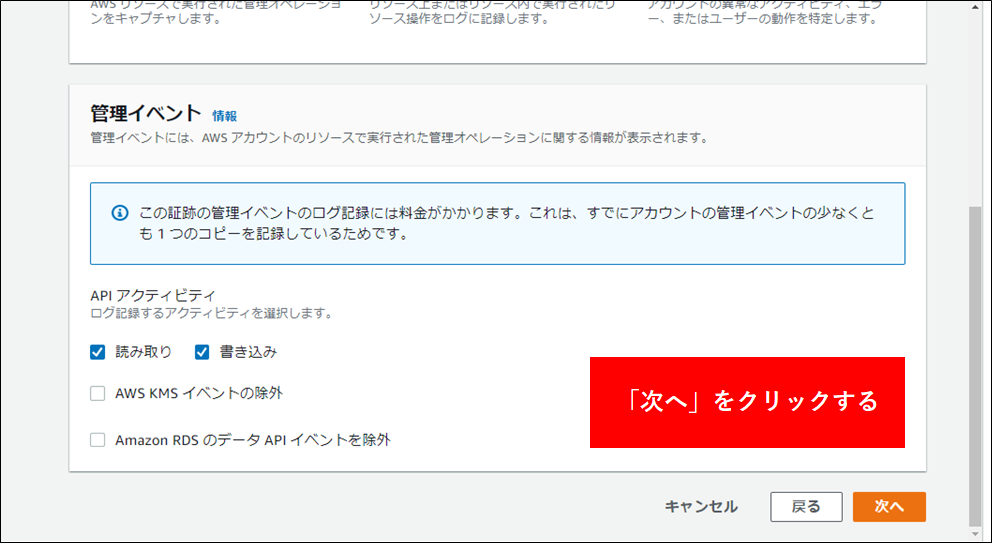
3.Athenaからクエリが実行できるようにする#
Info
以下の作業はログアカウントで実行します
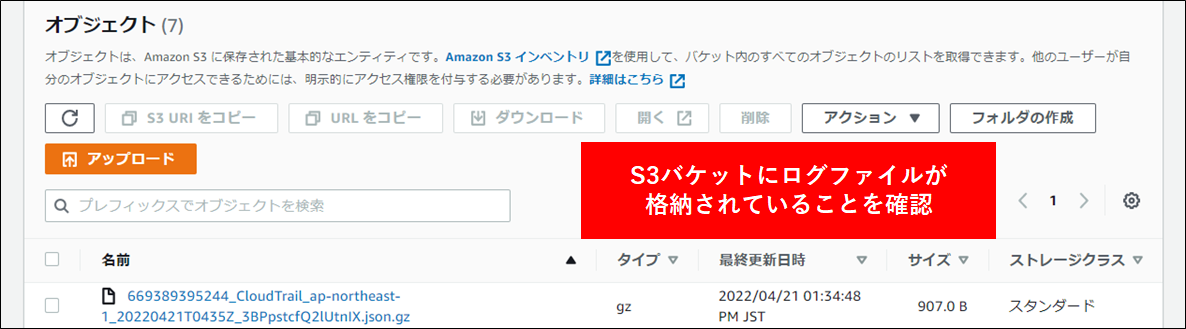
1.最初に ログアカウントの S3 に指定通りログが保存されていることを確認します。 S3 にアクセスし、設定済みのログを確認します。以下のように CloudTrail のバケットが作成されており、中に gz 形式のデータが保存されていることを確認します。
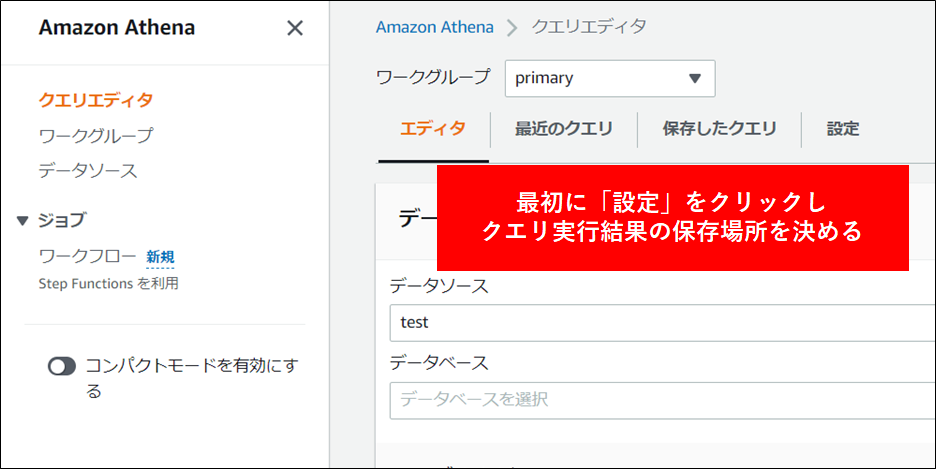
2.AWS 管理コンソールから Athena へアクセスします。
 {: style="width:740px"}
{: style="width:740px"}
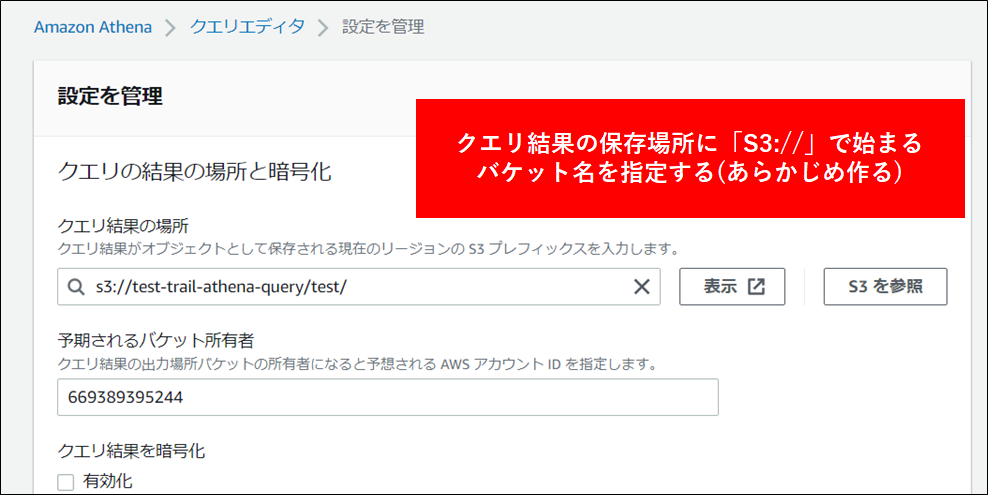
3.クエリを保存するバケットを指定します(手順は省略しますがあらかじめ作成しておきます)。
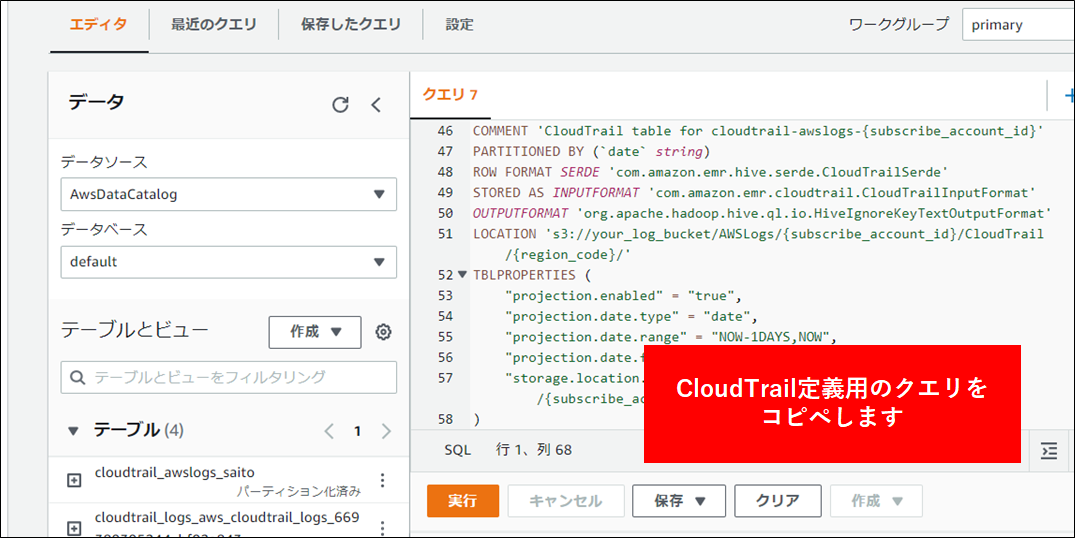
4.Athena の管理コンソールから テーブル を定義します。これにより CloudTrail のテーブルが作成されます。定義にあたっては以下の DDL をコピペして実行します。
CloudTrail は データサイズが大きくなり Athena の処理実行にも時間がかかることから、パーティションを設定します。
Info
行頭のテーブル名および LOCATION 部分など★がついた部分は適切な名称、位置に修正してください。 また、このテーブル定義はCloudTrailの管理画面から定義するクエリとほぼ同等のクエリです(こちらにはパーティションの作成が追加されています)。
Attention
データベース、テーブル、および列の名前には、小文字、数字、アンダースコア文字のみを使用できます。 ハイフンなどを利用することはできないため注意してください。
★CREATE EXTERNAL TABLE IF NOT EXISTS cloudtrail_awslogs_<組織名> (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING
)
COMMENT 'CloudTrail table for cloudtrail-awslogs-{subscribe_account_id}'
PARTITIONED BY (`timestamp` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
★LOCATION 's3://<バケット名>/AWSLogs/<アカウントID>/CloudTrail/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.timestamp.format'='yyyy/MM/dd',
'projection.timestamp.interval'='1',
'projection.timestamp.interval.unit'='DAYS',
'projection.timestamp.range'='2020/01/01,NOW',
'projection.timestamp.type'='date',
★'storage.location.template'='s3://<バケット名>/AWSLogs/<アカウントID>/CloudTrail/ap-northeast-1/${timestamp}')
Info
"projection.date.range" = "NOW-1DAYS,NOW"で日付の範囲を指定しています。
これは昨日から今日までの範囲を指定しています。
複数のアカウントを指定したい場合は下記のように記述することができます。 (組織で有効化している場合を想定しております。)
Attention
★がついている行の<>は環境に合わせて置換してください。
★CREATE EXTERNAL TABLE IF NOT EXISTS cloudtrail_awslogs_<組織名> (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING
)
COMMENT 'CloudTrail table'
PARTITIONED BY(`account` string, `date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
★LOCATION 's3://<バケット名>/AWSLogs/<組織ID>/<アカウントID>/CloudTrail/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.account.type" = "enum",
★"projection.account.values" = "111111111111,222222222222",
"projection.date.type" = "date",
"projection.date.range" = "NOW-1DAYS,NOW",
"projection.date.format" = "yyyy/MM/dd",
★"storage.location.template" = "s3://<バケット名>/AWSLogs/<組織ID>/${account}/CloudTrail/ap-northeast-1/${date}"
)
パーティションおよびテーブルの定義は複数のアカウントの場合は、その分だけ作成します。つまりテーブルと1:1で作成することになります。
5.テスト用のクエリを実行します。画面左側のテーブル一覧から、赤矢印部分をクリックしテーブルのプレビューをクリックします。
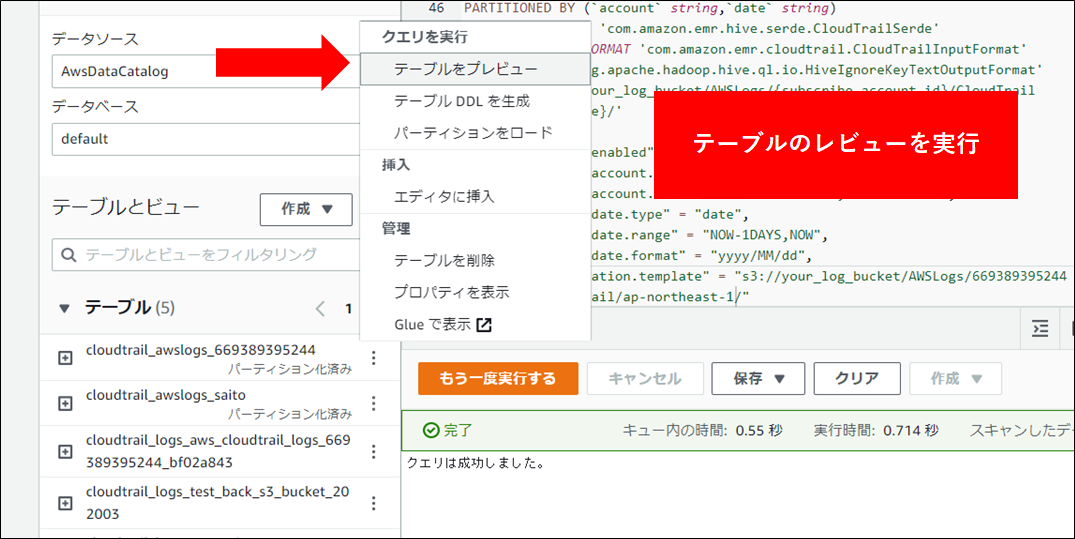
6.結果が表示されます。結果を CSV で出力するには、赤矢印部分をクリックします。
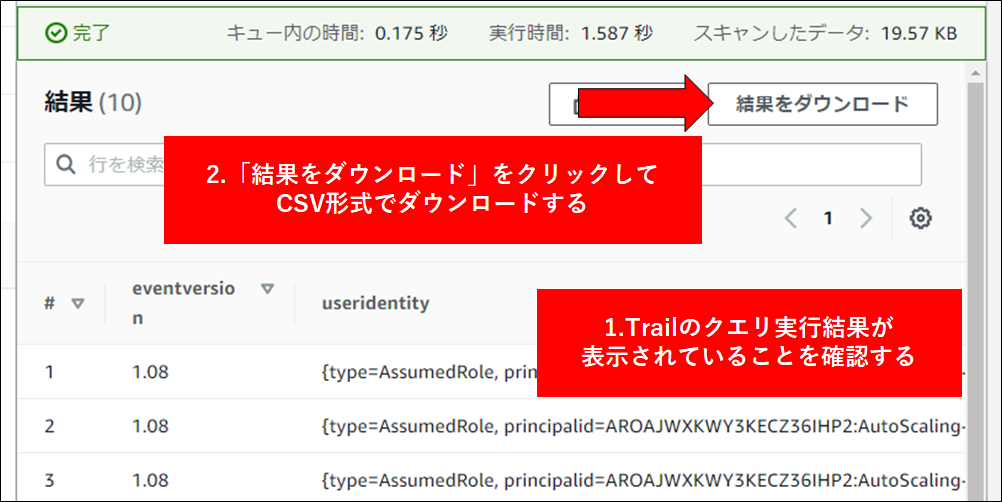
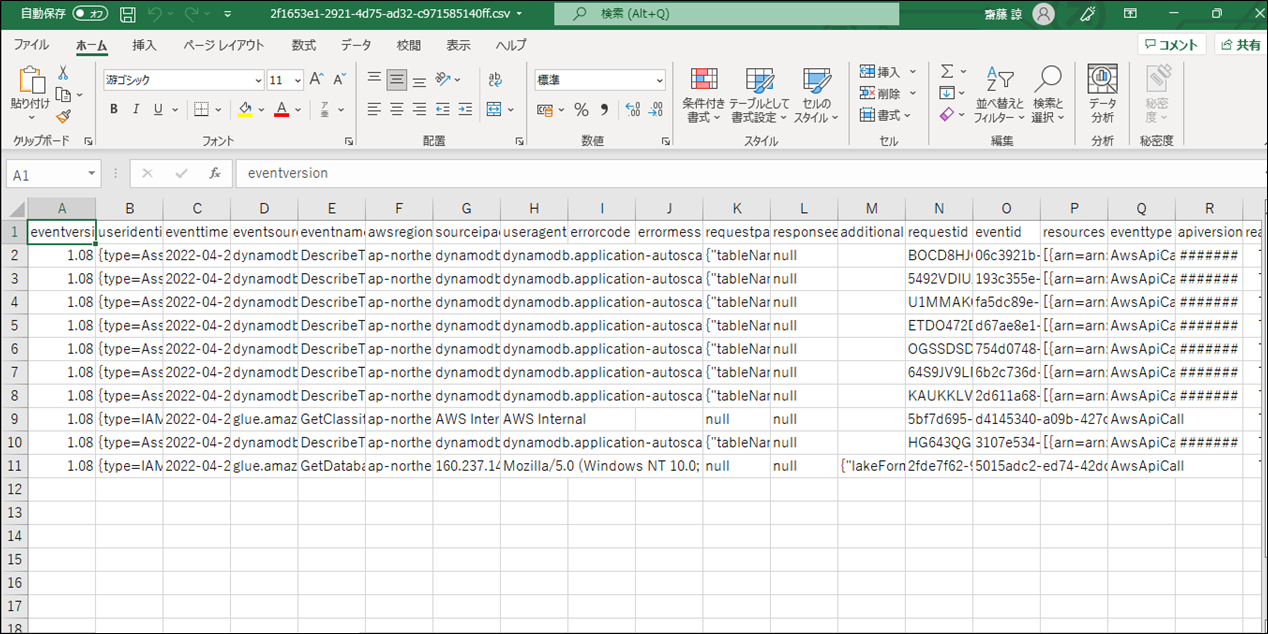
7.ダウンロードされた結果を Excel で確認します。
4.CloudTrail クエリサンプル#
Info
クエリサンプルを実行するにあたり、以下のサンプルはパーティションが考慮されていないため、全期間(5年分のログがあれば5年分)をスキャンします。このため、期間が長い場合や環境が大きい場合クエリに時間がかかることがあります(数分~十数分程度かかります)。またスキャン量 1TB に対して5ドルの費用が発生するので注意してください。where句を入れることで、対象操作者などの絞り込みが可能です。このため、SQL クエリを書くことになれていない方は、本文中の SQL のサンプルをベースにクエリを実行するようにしてください。
1.24時間以内のAWSコンソールへのログイン
SELECT useridentity.username,sourceipaddress,eventtime,additionaleventdata
FROM "default"."cloudtrail_iogs_table"
WHERE eventname = 'ConsoleLogin'
and eventtime >= '2017-02-17Too:00:00Z'
and eventtime < '2017-02-17Too:00:00Z';
2.24時間以内の失敗したAWSコンソールへのログイン
SELECT useridentity.username,sourceipaddress,eventtime,additionaleventdata
FROM "default"."cloudtrail_iogs_table"
WHERE eventname = 'ConsoleLogin'
and useridentity.username = 'HIDDEN_DUE_TO_SECURITY_REASONS'
and eventtime >= '2017-02-17Too:00:00Z'
and eventtime < '2017-02-17Too:00:00Z';
3.IAMユーザーの操作履歴
SELECT useridentity.type,useridentity.username,eventsource,eventname,sourceipaddress,eventtime,awsregion,additionaleventdata
FROM "default"."cloudtrail_iogs_table"
WHERE 1 = 1
and useridentity.type = 'IAMUser'
--and useridentity.name != 'awsadmin'
and eventtime >= '2019-07-01Too:00:00Z'
and eventtime < '2019-07-17Too:00:00Z'
order by eventtime desc
LIMIT 500;
4.IAMロールの操作履歴
SELECT useridentity.type,useridentity.sessioncontext.sessionissuer.username,eventsource,eventname,sourceipaddress,eventtime,awsregion,additionaleventdata
FROM "default"."cloudtrail_iogs_table"
WHERE 1 = 1
and useridentity.type = 'AssumedRole'
and eventtime >= '2019-07-01Too:00:00Z'
and eventtime < '2019-07-17Too:00:00Z'
LIMIT 500;